
关于多功能引擎ES知识的学习
想必大家都知道ES,一款非常好用的工具,但是我还是想详细解释一下它的概念:ES全称Elasticsearch,是一个开源的高扩展的分布式全文搜索引擎,是整个Elastic Stack技术栈的核心。它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。可以看出ES功能非常强大,所以现在国内外很多公司都在使用。
看到这里又会有人说了:传统数据库不行吗?还真不行(也不是不行,就是效果不好),哈哈哈哈。传统数据库实现全文检索的话很鸡肋,因为一般不会用传统数据库存非结构化的像文本字段等数据。进行全文检索需要扫描整个表,如果数据量大的话即使对SQL的语法优化,也收效甚微。建立了索引,但是维护起来也很麻烦,对于insert和update操作都会重新构建索引。基于以上原因可以分析得出,在一些生产环境中,使用常规的搜索方式,性能是非常差的:
- 搜索的数据对象是大量的非结构化的文本数据
- 文件记录量达到数十万或数百万个甚至更多
- 支持大量基于交互式文本的查询
- 需求非常灵活的全文搜索查询
- 对高度相关的搜索结果的有特殊需求,但是没有可用的关系数据库可以满足
- 对不同记录类型、非文本数据操作或安全事务处理的需求相对较少的情况
为了解决这些问题,我们就需要全文搜索引擎,它的工作原理是计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户。这个过程类似于通过字典中的检索字表查字的过程。
首先我们来讲讲 ES 入门知识
数据格式
Elasticsearch 是面向文档型数据库,一条数据在这里就是一个文档。将 Elasticsearch 里存储文档数据和关系型数据库 MySQL 存储数据的概念进行一个类比
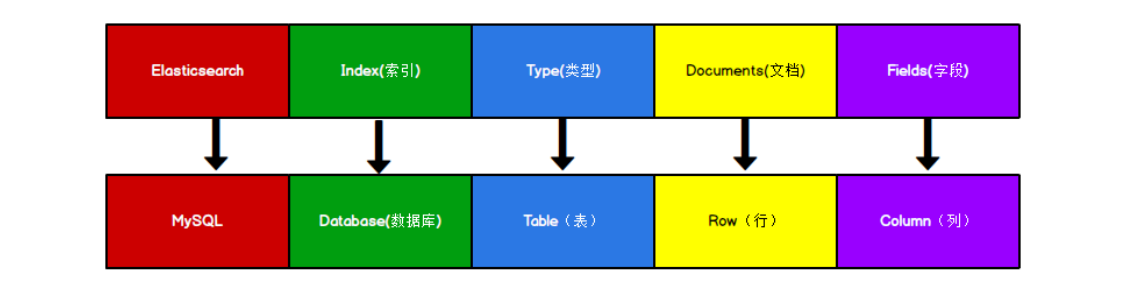
Elasticsearch 7.X 中, Type 的概念已经被删除
HTTP操作
索引操作
1)创建索引
向 ES 服务器发 PUT 请求 :http://127.0.0.1:9200/shopping

2)查看所有索引
向 ES 服务器发 GET 请求 :http://127.0.0.1:9200/_cat/indices?v

3)查看单个索引
向 ES 服务器发 GET 请求 :http://127.0.0.1:9200/shopping

4)删除索引
向 ES 服务器发 DELETE 请求 :http://127.0.0.1:9200/shopping

文档操作
1)创建文档
向 ES 服务器发 POST 请求 :http://127.0.0.1:9200/shopping/_doc
请求体内容为:
{
"title":"小米手机",
"category":"小米",
"images":"http://www.gulixueyuan.com/xm.jpg",
"price":3999.00
}
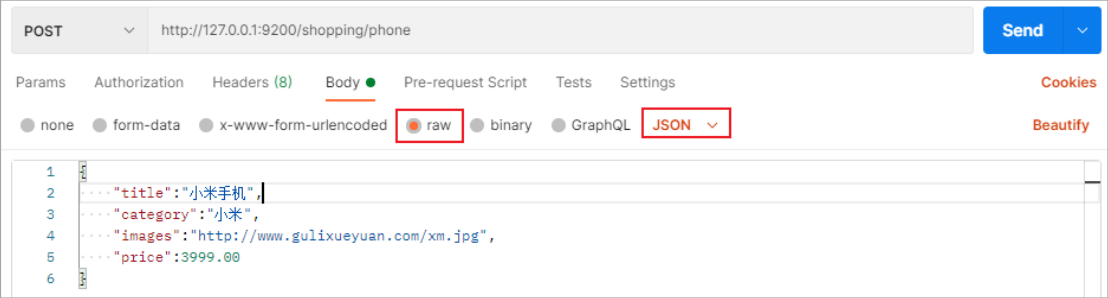
上面的数据创建后,由于没有指定数据唯一性标识(ID),默认情况下,ES 服务器会随机生成一个。
如果想要自定义唯一性标识,需要在创建时指定:http://127.0.0.1:9200/shopping/_doc/1
2)查看文档
向 ES 服务器发 GET 请求 :http://127.0.0.1:9200/shopping/_doc/1
3)修改文档
向 ES 服务器发 POST 请求 :http://127.0.0.1:9200/shopping/_doc/1
请求体内容为:
{
"title":"华为手机",
"category":"华为",
"images":"http://www.gulixueyuan.com/hw.jpg",
"price":4999.00
}
4)修改字段
向 ES 服务器发 POST 请求 :http://127.0.0.1:9200/shopping/_update/1
请求体内容为:
{
"doc": {
"price":3000.00
}
}
5)删除文档
删除一个文档不会立即从磁盘上移除,它只是被标记成已删除(逻辑删除)
向 ES 服务器发 DELETE 请求 :http://127.0.0.1:9200/shopping/_doc/1
6)条件删除文档
向 ES 服务器发 POST 请求 :http://127.0.0.1:9200/shopping/_delete_by_query
请求体内容为:
{
"query":{
"match":{
"price":4000.00
}
}
}
映射操作
有了索引库,等于有了数据库中的 database。接下来就需要创建索引库(index)中的映射了,类似于数据库(database)中的表结构(table)。创建数据库表需要设置字段名称,类型,长度,约束等;索引库也一样,需要知道这个类型下有哪些字段,每个字段有哪些约束信息,这就叫做映射(mapping)。
1)创建映射
向 ES 服务器发 PUT 请求 :http://127.0.0.1:9200/student/_mapping
请求体内容为:
{
"properties": {
"name":{
"type": "text",
"index": true
},
"sex":{
"type": "text",
"index": false
},
"age":{
"type": "long",
"index": false
}
}
}
映射数据说明:
字段名:任意填写,下面指定许多属性,例如:title、subtitle、images、price
type:类型,Elasticsearch 中支持的数据类型非常丰富,说几个关键的:
String 类型,又分两种:
text:可分词
keyword:不可分词,数据会作为完整字段进行匹配 Numerical:数值类型,分两类
基本数据类型:long、integer、short、byte、double、float、half_float
浮点数的高精度类型:scaled_float
Date:日期类型
Array:数组类型
Object:对象
index:是否索引,默认为 true,也就是说你不进行任何配置,所有字段都会被索引。
true:字段会被索引,则可以用来进行搜索
false:字段不会被索引,不能用来搜索
store:是否将数据进行独立存储,默认为 false
原始的文本会存储在_source 里面,默认情况下其他提取出来的字段都不是独立存储的,是从_source 里面提取出来的。当然你也可以独立的存储某个字段,只要设置”store”: true 即可,获取独立存储的字段要比从_source 中解析快得多,但是也会占用更多的空间,所以要根据实际业务需求来设置。
analyzer:分词器,这里的 ik_max_word 即使用 ik 分词器,后面会有专门的章节学习
2)查看映射
向 ES 服务器发 GET 请求 :http://127.0.0.1:9200/student/_mapping
3)索引映射关联
向 ES 服务器发 PUT 请求 :http://127.0.0.1:9200/student1
请求体内容为:
{
"settings": {},
"mappings": {
"properties": {
"name":{
"type": "text",
"index": true
},
"sex":{
"type": "text",
"index": false
},
"age":{
"type": "long",
"index": false
}
}
}
}
高级查询
然后再说说 ES 进阶知识
核心概念
索引(Index)
一个索引就是一个拥有几份相似特征的文档的集合。一个索引由一个名字来标识(必须全部是小写字母),并且当我们要对这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。在一个集群中,可以定义任意多的索引。
能搜索的数据必须索引,这样的好处是可以提高查询速度,比如:新华字典前面的目录就是索引的意思,目录可以提高查询速度。
Elasticsearch 索引的精髓:一切设计都是为了提高搜索的性能
类型(Type)
一个类型是你的索引的一个逻辑上的分类/分区。ElasticSearch 7.x 默认不再支持自定义索引类型(默认类型为:_doc)。
文档(Document)
一个文档是一个可被索引的基础信息单元,也就是一条数据。文档以 JSON 格式来表示,而 JSON 是一个
到处存在的互联网数据交互格式。字段(Field)
相当于是数据表的字段,对文档数据根据不同属性进行的分类标识。
映射(Mapping)
分片(Shards)
被混淆的概念是,一个 Lucene 索引 我们在 Elasticsearch 称作 分片 。 一个 Elasticsearch 索引 是分片的集合。 当 Elasticsearch 在索引中搜索的时候, 他发送查询到每一个属于索引的分片(Lucene 索引) ,然后合并每个分片的结果到一个全局的结果集
副本(Replicas)
分配(Allocation)
将分片分配给某个节点的过程,包括分配主分片或者副本。如果是副本,还包含从主分片复制数据的过程。这个过程是由 master 节点完成的。
系统架构
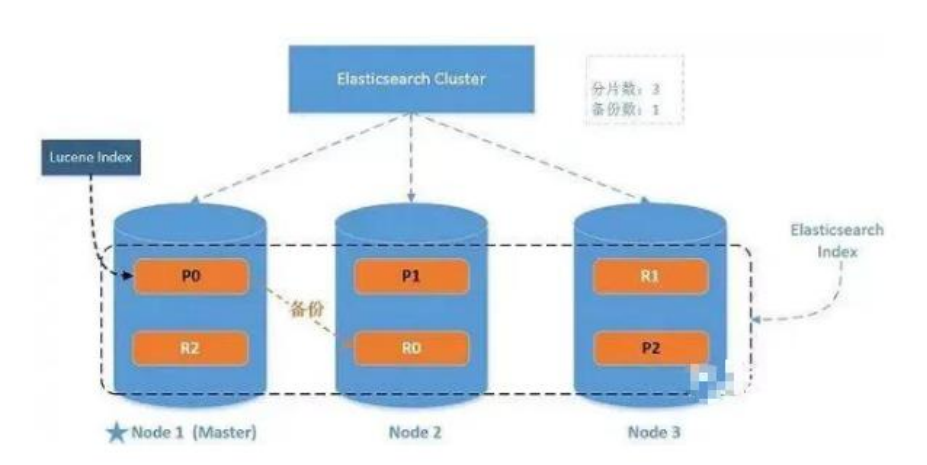
当一个节点被选举成为主节点时, 它将负责管理集群范围内的所有变更,例如增加、删除索引,或者增加、删除节点等。 而主节点并不需要涉及到文档级别的变更和搜索等操作,所以当集群只拥有一个主节点的情况下,即使流量的增加它也不会成为瓶颈。
作为用户,我们可以将请求发送到集群中的任何节点 ,包括主节点。 每个节点都知道任意文档所处的位置,并且能够将我们的请求直接转发到存储我们所需文档的节点。 无论我们将请求发送到哪个节点,它都能负责从各个包含我们所需文档的节点收集回数据,并将最终结果返回給客户端。 Elasticsearch 对这一切的管理都是透明的。
路由计算
当索引一个文档的时候,文档会被存储到一个主分片中。Elasticsearch 如何知道一个文档应该存放到哪个分片中呢?当我们创建文档时,它如何决定这个文档应当被存储在分片 1 还是分片 2 中呢?
通过路由计算我们就能知道以上答案

routing 默认是文档的_id,也可以设置成自定义值。number_of_primary_shards 是主分片的数量
分片控制
我们可以发送请求到集群中的任一节点。 每个节点都有能力处理任意请求。 每个节点都知道集群中任一文档位置,所以可以直接将请求转发到需要的节点上。 在下面的例子中,将所有的请求发送到 Node1,我们将其称为协调节点(coordinating node) 。
当发送请求的时候,为了扩展负载,更好的做法是轮询集群中所有的节点
写流程
新建、索引和删除请求都是写操作, 必须在主分片上面完成之后才能被复制到相关的副本分片
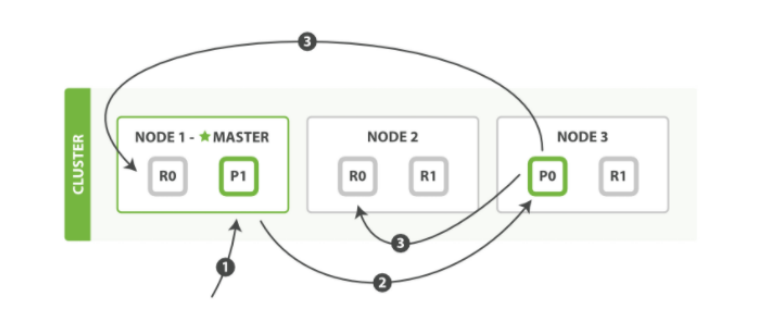
- 客户端向Node1发送新建、索引或者删除请求
- 节点使用文档的 _id 确定文档属于分片 0 。请求会被转发到 Node3,因为分片 0 的主分片目前被分配在 Node3 上
- Node3 在主分片上面执行请求。如果成功了,它将请求并行转发到 Node1 和 Node2的副本分片上。一旦所有的副本分片都报告成功, Node3 将向协调节点报告成功,协调节点向客户端报告成功
读流程
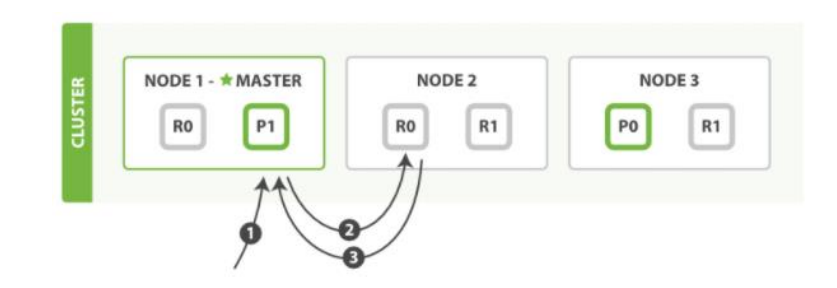
- 客户端向 Node1 发送获取请求
- 节点使用文档的 _id 来确定文档属于分片 0 。分片 0 的副本分片存在于所有的三个节点上。 在这种情况下,它将请求转发到 Node2
- Node2 将文档返回给 Node1,然后将文档返回给客户端
更新流程
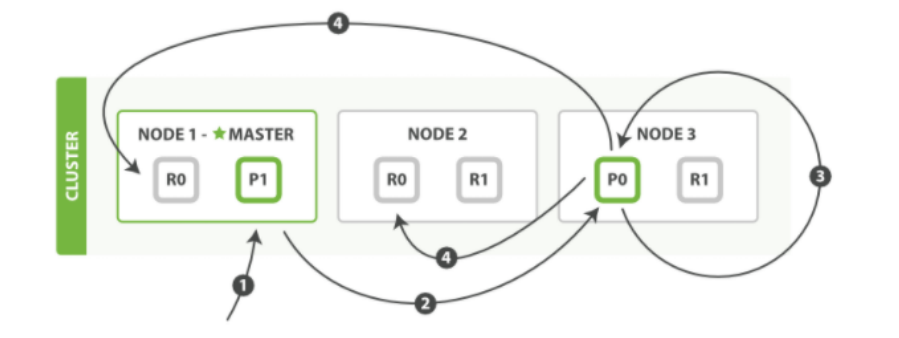
- 客户端向 Node1 发送更新请求
- 它将请求转发到主分片所在的 Node3
- Node3 从主分片检索文档,修改 _source 字段中的 JSON ,并且尝试重新索引主分片的文档。 如果文档已经被另一个进程修改,它会重试步骤 3 ,超过 retry_on_conflict 次后放弃
- 如果 Node3 成功地更新文档,它将完整的新版本的文档并行转发到 Node1 和 Node2 上的副本分片,重新建立索引。一旦所有副本分片都返回成功, Node3 向协调节点也返回成功,协调节点向客户端返回成功
分片原理
分片是 Elasticsearch 最小的工作单元。但是究竟什么是一个分片,它是如何工作的?
文本字段中的每个单词需要被搜索,对数据库意味着需要单个字段有索引多值的能力。最好的支持是一个字段多个值
需求的数据结构是倒排索引
倒排索引
首先来看看什么是正向索引
正向索引,就是搜索引擎会将待搜索的文件都对应一个文件 ID,搜索时将这个ID 和搜索关键字进行对应,形成 K-V 对,然后对关键字进行统计计数
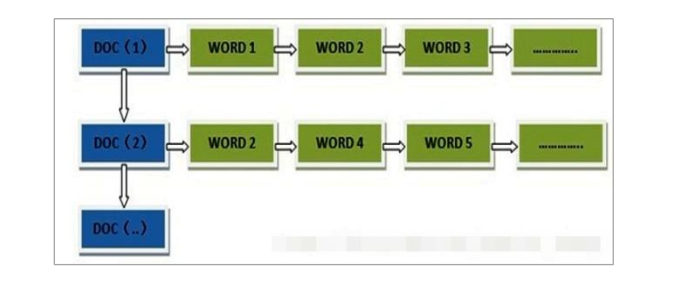
但是搜索引擎中的文档的数目是个天文数字,这样的索引结构根本无法满足实时返回结果要求,所以搜索引擎会将正向索引重新构建为倒排索引
倒排索引,即把文件ID对应到关键词的映射转换为关键词到文件ID的映射,每个关键词都对应着一系列的文件,这些文件中都出现这个关键词
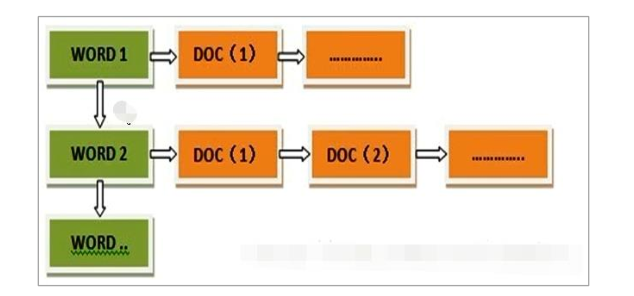
分词和标准化的过程称为分析
倒排索引被写入磁盘后是不可改变的:它永远不会修改
不变性有重要的价值:
- 不需要锁。如果你从来不更新索引,你就不需要担心多进程同时修改数据的问题
- 一旦索引被读入内核的文件系统缓存,便会留在哪里,由于其不变性。只要文件系统缓存中还有足够的空间,那么大部分读请求会直接请求内存,而不会命中磁盘。这提供了很大的性能提升
- 其它缓存(像 filter 缓存),在索引的生命周期内始终有效。它们不需要在每次数据改变时被重建,因为数据不会变化
- 写入单个大的倒排索引允许数据被压缩,减少磁盘 I/O 和 需要被缓存到内存的索引的使用量
动态更新索引
如何在保留不变性的前提下实现倒排索引的更新?
更新方案:用更多的索引。通过增加新的补充索引来反映新近的修改,而不是直接重写整个倒排索引。每一个倒排索引都会被轮流查询到,从最早的开始查询完后再对结果进行合并。
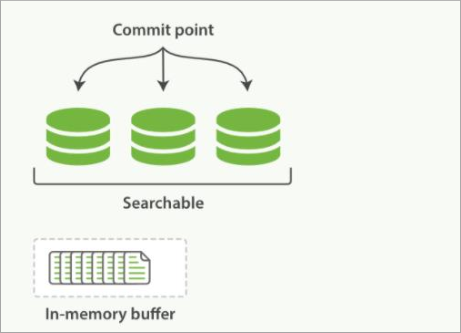
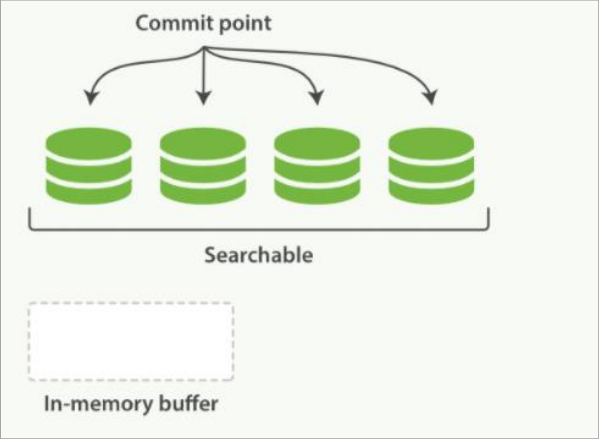
按段搜索
按段搜索会以如下流程执行:
新文档被收集到内存索引缓存

image-20230521184530401 不时地, 缓存被提交
(1) 一个新的段–一个追加的倒排索引—被写入磁盘。
(2) 一个新的包含新段名字的 提交点 被写入磁盘
(3) 磁盘进行 同步 — 所有在文件系统缓存中等待的写入都刷新到磁盘,以确保它们被写入物理文件新的段被开启,让它包含的文档可见以被搜索
内存缓存被清空,等待接收新的文档
image-20230521184659247
最后聊一下如何对 ES 进行优化
硬件选择
- 使用SSD。固态硬盘比机械硬盘优秀很多
- 使用 RAID 0。条带化 RAID 会提高磁盘 I/O,代价显然就是当一块硬盘故障时整个就故障了。不要使用镜像或者奇偶校验 RAID 因为副本已经提供了这个功能
- 另外,使用多块硬盘,并允许 Elasticsearch 通过多个 path.data 目录配置把数据条带化分配到它们上面
- 不要使用远程挂载的存储,比如 NFS 或者 SMB/CIFS。这个引入的延迟对性能来说完全是背道而驰的
分片策略
- 标题: 关于多功能引擎ES知识的学习
- 作者: 宣胤
- 创建于: 2023-05-11 09:57:47
- 更新于: 2023-05-21 19:04:06
- 链接: http://xuanyin02.github.io/2023/051139179.html
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。