
关于大数据处理引擎Spark知识的学习
第一章:RDD详解
1.1 为什么需要RDD
分布式计算需要:
- 分区控制
- Shuffle控制
- 数据存储\序列化\发送
- 数据计算API 等一系列功能
这些功能,不能简单的通过Python内置的本地集合对象(如List\字典等)去完成。我们在分布式框架中,需要有一个统一的数据抽象对象,来实现上述分布式计算所需功能。这个抽象对象,就是RDD。
1.2 什么是RDD
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,代表一个不可变、可分区、里面的元素可并行计算的集合。
Resilient:Spark优先把数据放到内存中,如果内存放不下,就会放到磁盘里面,程序进行自动的存储切换
在RDD进行转换和动作的时候,会形成RDD的Lineage依赖链,当某一个RDD失效的时候,可以通过重新计算上游的RDD来重新生成丢失的RDD数据。
Spark把这个Job执行模型抽象为通用的有向无环图DAG,可以将多Stage的任务串联或并行执行,调度引擎自动处理Stage的失败以及Task的失败
Task如果失败会自动进行特定次数的重试,默认重试次数为4
Stage如果失败会自动进行特定次数的重试,默认重试次数为4
数据分片的高度弹性:可以根据业务的特征,动态调整数据分片的个数,提升整体的应用执行效率
Distributed:RDD中的数据是分布式存储的,可用于分布式计算。RDD的数据是跨机器存储的(跨进程)
Dataset:一个数据集合,用于存放数据的。List、Dict、Array本地集合(数据全部在一个进程内部)
不可变:不可变集合,变量的声明使用val
分区的:集合的数据被划分为很多部分,每部分称为分区Partition
并行计算:集合中的数据可以被并行的计算处理,每个分区数据被一个task处理
1.3 RDD的五大特性
前三个特性每个RDD都具备的,后两个特征是可选的:
- RDD是有分区的
- 计算方法都会作用到每一个分片(分区)之上
- RDD之间是有相互依赖的关系的
- KV型RDD可以有分区器
- RDD分区数据的读取会尽量靠近数据所在地
第二章 RDD编程入门
第三章 RDD的持久化
3.1 RDD的数据的过程数据
RDD之间相互迭代计算(Transformation的转换),当执行开启后,新的RDD的生成,代表老RDD的消失
RDD的数据是过程数据,只在数据的处理过程中存在,一旦处理完成,就不见了。这个特性可以最大化的利用资源,老旧RDD没用了,就从内存中清理,给后续的计算腾出内存空间
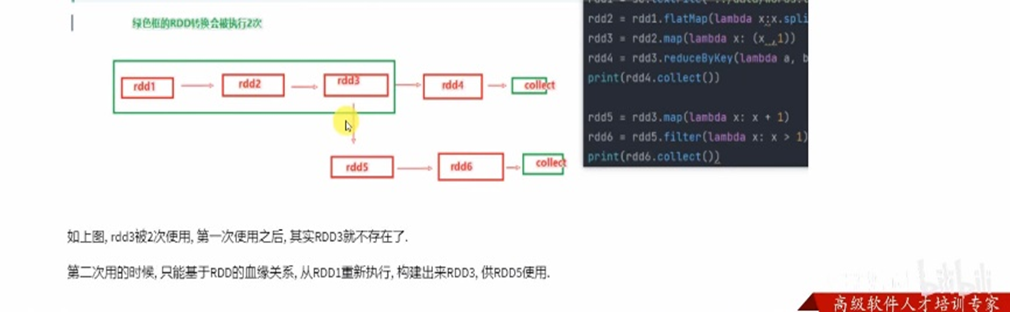
为了不重新从rdd1开始构建rdd3,所以要使用rdd的持久化技术
3.2 RDD Cache
对于上述的场景,肯定要执行优化,优化就是:rdd3如果不消失,那么rdd1->rdd2->rdd3这个链条就不会执行2次,或者更多次
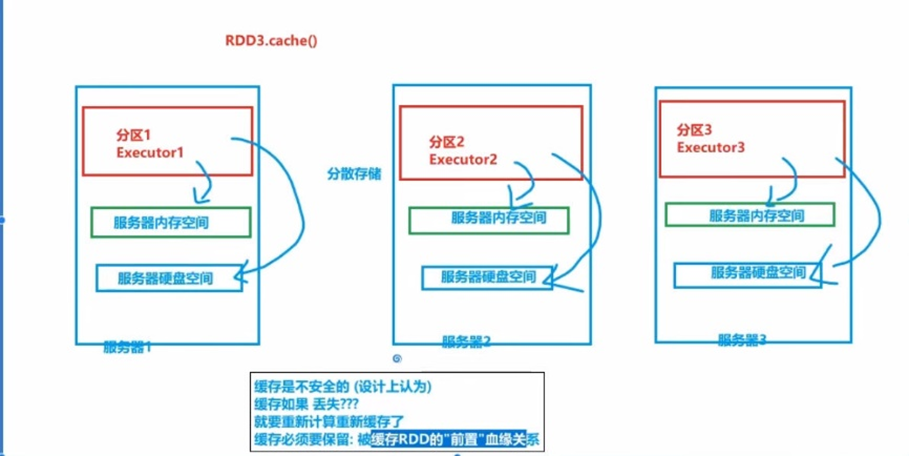
RDD的缓存技术:Spark提供了缓存的API,可以让我们通过调用API,将指定的RDD的数据保留在内存或者硬盘上

3.3 RDD CheckPoint
CheckPoint技术,也是将RDD的数据,保存起来但是它仅支持硬盘存储
并且:①它被设计认为是安全的;②不保留血缘关系。
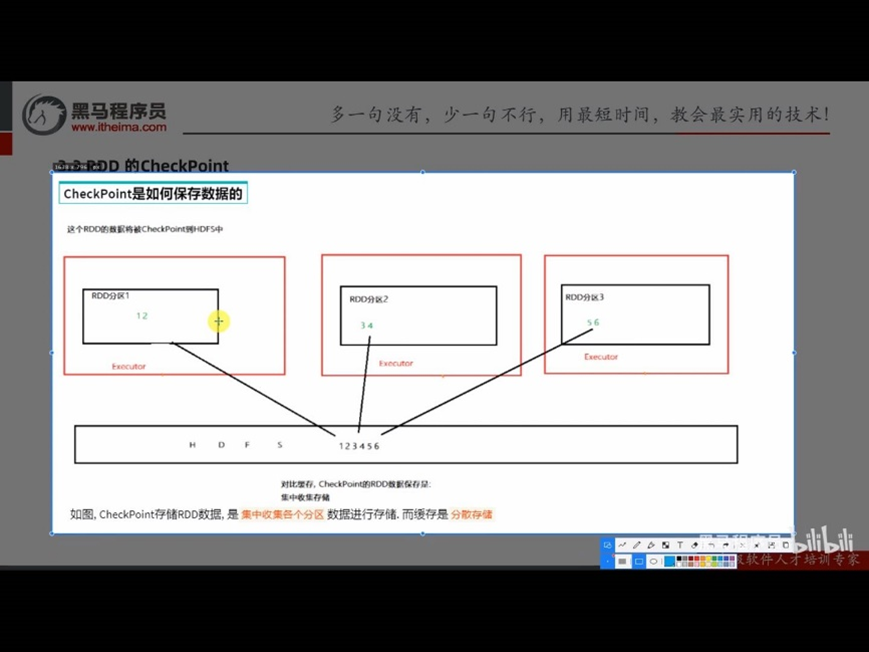
Cache(缓存)与CheckPoint的对比:
- CheckPoint不管分区数量多少,风险是一样的,缓存分区越多,风险越高
- CheckPoint支持写入HDFS,缓存不行,HDFS是高可靠存储,CheckPoint被认为是安全的
- CheckPoint不支持内存,缓存可以,缓存如果写内存,性能比CheckPoint要好一些
- CheckPoint因为被设计认为是安全的,所以不保留血缘关系,而缓存因为设计上认为不安全,所以保留
设置CheckPoint第一件事情,选择RDD的保存路径
如果是Local模式,可以支持本地文件系统,如果在集群运行,千万要用HDFS
Sc.setCheckpointDir(“hdfs:node1:9000/out/xxx”)
用的时候,直接调用checkpoint算子即可:
Rdd.checkpoint()
第四章 Spark案例练习
第五章 共享变量
5.1 广播变量
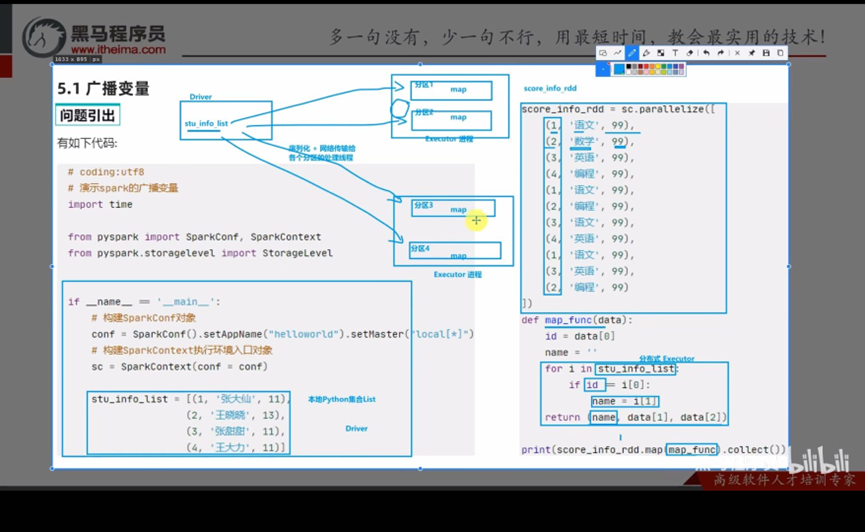
!!!Executor是进程,进程内资源共享,一个Executor中有两个分区,那这两个分区就可以共享资源。Stu_info_list由Driver发送给每个分区,但是又可以共享,那么Executor中就有了两份相同的资源,造成内存的浪费和网络传输成本的增加。
解决方案:广播变量
使用方式:
#1、将本地list标记成广播变量即可
Broadcast = sc.broadcast(stu_info_list)
#2、使用广播变量,从broadcast对象中取出本地list对象即可
Value = broadcast.value
#也就是 先放进去broadcast内部,然后从broadcast内部取出来用,中间传输的是broadcast这个对象了
#只要中间传输的是broadcast对象,spark就会留意,只会给每个Ececutor发一份了,而不是傻傻的哪个分区要都给
5.2 累加器
需求:想要对map算子计算中的数据,进行技术累加,得到全部数据计算完后的累加结果
因为我们初始化的count标志从Driver发送给Ececutor是发送的数值,不像指针地址那种
第六章 Spark内核调度
6.1 DAG
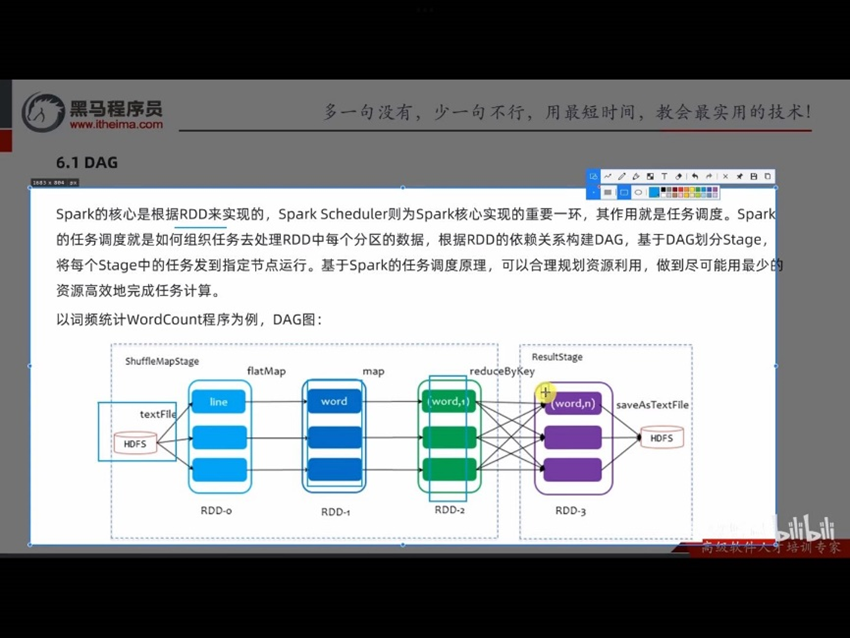
DAG:有向无环图。有方向没有形成闭环的一个执行流程图
一个Action会将前面一串的RDD依赖关系(Transformation)执行,也就是一个Action会产生一个DAG图
前面我们写的搜索日志分析案例,3个需求就是3个Action,就产生了3个DAG
一个Action会产生一个Job(一个应用程序内的子任务),每一个Job有各自的DAG图
结论:Job和Action
1个Action会产生1个DAG,如果代码中有3个Action就产生3个DAG
一个Action会产生一个DAG,会在程序运行中产生一个Job
所以:1个Action = 1个DAG = 1个Job
如果一个代码中,写了3个Action,那么这个代码运行起来产生3个Job,每个Job有自己的DAG
一个代码运行起来,在Spark中称之为:Application
层级关系:1个Application中,可以有多个Job,每一个Job内含一个DAG,同时每一个Job都是由一个Action产生的
DAG是Spark代码的逻辑执行图,这个DAG的最终作用是:为了构建物理上的Spark详细执行计划而生,所以,由于Spark是分布式(多分区)的,那么DAG和分区之间也是有关联的
6.2 DAG的宽窄依赖和阶段划分
宽窄依赖:
在Spark RDD前后之间的关系,分为:窄依赖、 宽依赖
窄依赖:父RDD的一个分区,全部将数据发给子RDD的一个分区
宽依赖:父RDD的一个分区,将数据发给子RDD的多个分区
宽依赖还有一个别名:shuffle
阶段划分:
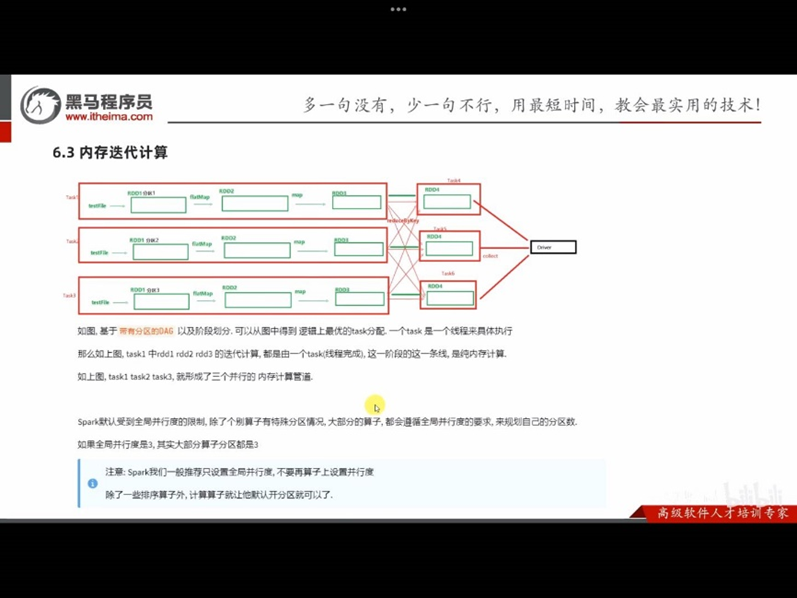
对于Spark来说,会根据DAG,按照宽窄依赖,划分不同的DAG阶段
划分依据:从后往前,遇到宽依赖,就分出一个阶段,称之为stage
在stage的内部,一定都是:窄依赖
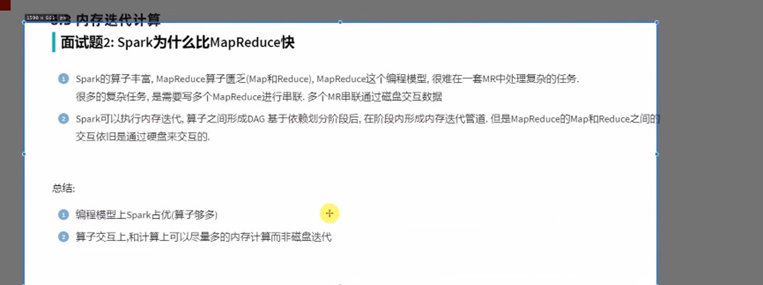
6.3 内存迭代运算

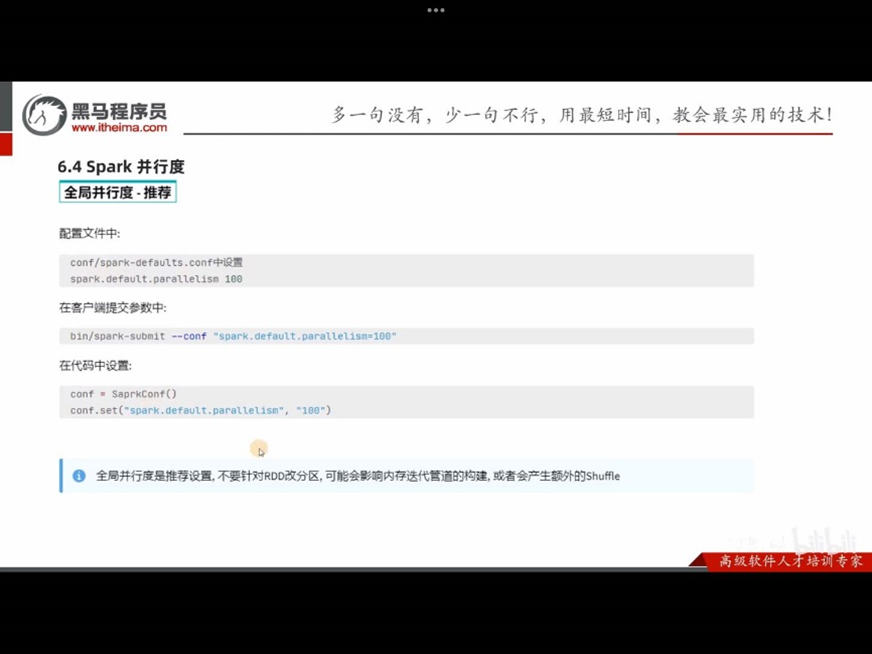
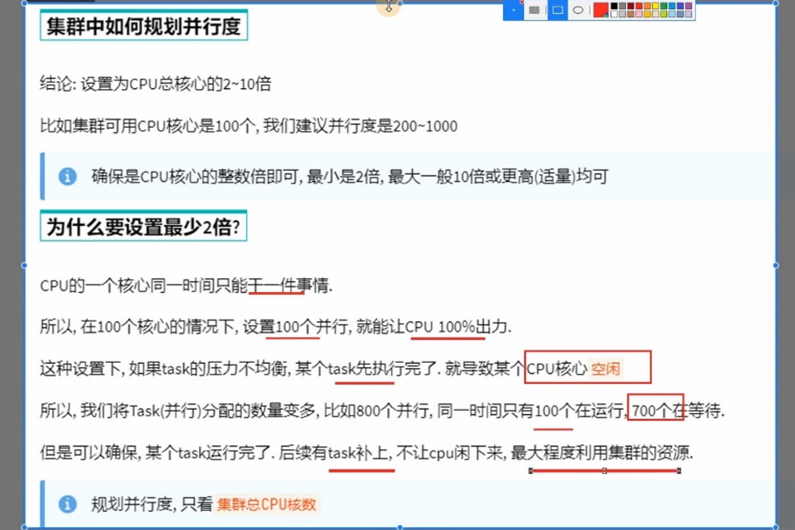
6.4 Spark并行度
Spark的并行:在同一时间内,有多少个task在同时运行
并行度:并行能力的设置
比如设置并行度为6,其实就是要6个task并行在跑
在有了6个task并行的前提下,rdd的分区就被规划成6个分区了
6.5 Spark任务调度
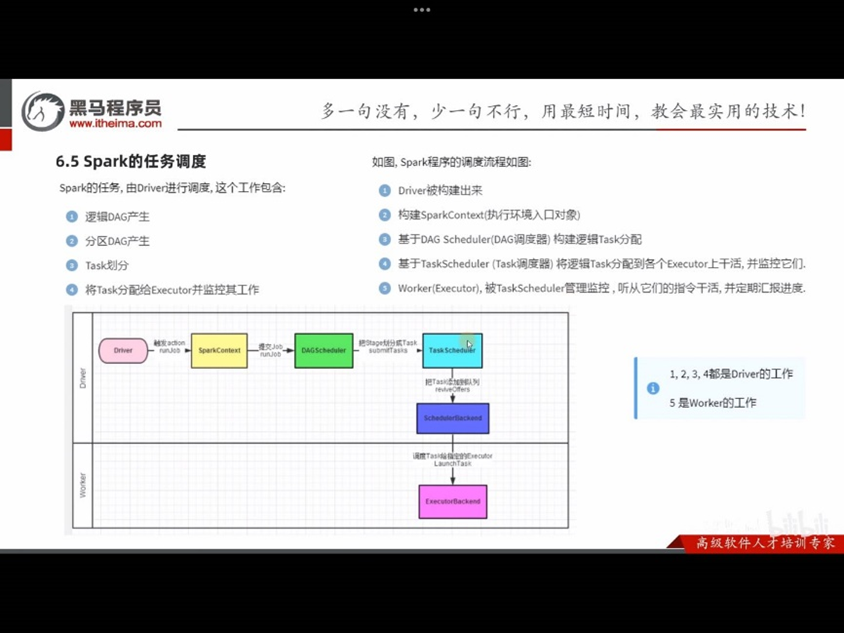
DAG调度器:工作内容:将逻辑的DAG图进行处理,最终得到逻辑上的Task划分
Task调度器:工作内容:基于DAG调度器的产出,来规划这些逻辑的task,应该在哪些物理的executor上运行,以及监控管理它们的运行
Spark架构体系
StandAlone模式是spark⾃带的集群运⾏模式,不依赖其他的资源调度框架,部署起来简单。
StandAlone模式⼜分为client模式和cluster模式,本质区别是Driver运⾏在哪⾥,如果Driver运⾏在SparkSubmit进程中就是Client模式,如果Driver运⾏在集群中就是Cluster模式。
standalone client模式

standalone cluster模式

Spark On YARN cluster模式

- client向ResourceManager申请资源,返回一个application ID
- client上传spark jars下面的jar包、自己写的jar包和配置
- ResourceManager随机找一个资源充足的NodeManager
- 然后通过RPC让NodeManager从HDFS上下载jar包和配置,启动ApplicationMaster
- ApplicationMaster向ResourceManager申请资源
- ResourceManager中的调度器找到符合条件的NodeManager,将NodeManager的信息返回给ApplicationMaster
- ApplicationMaster跟返回的NodeManager进行通信
- NodeManager从HDFS下载依赖
- NodeManager启动Executor
- Executor启动之后反向向ApplicationMaster [Driver]注册
- 标题: 关于大数据处理引擎Spark知识的学习
- 作者: 宣胤
- 创建于: 2023-05-19 22:23:10
- 更新于: 2023-05-20 00:23:02
- 链接: http://xuanyin02.github.io/2023/051959676.html
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。