
关于数据仓库hive知识的学习(1)
hive在离线数据仓库中十分常用,那么hive是什么呢?有什么用?它是怎么工作的?怎么使用它?下面这篇文章将一一解答你的问题!
第1章 hive入门
1.1 什么是hive
hive是基于hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能(HQL)。
1)hive处理的数据存储在HDFS
2)hive分析数据底层的实现是Mapreduce/Spark(分布式运行框架)
3)执行程序运行在yarn上
1.2 hive的优缺点
优点
- 操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)
- 避免了去写Mapreduce,减少开发人员的学习成本
- hive的执行延迟比较高,因此hive常用于数据分析,对实时性要求不高的场合(历史数据分析等)
- hive优势在于处理大数据,对于处理小数据没有优势,因为hive的执行延迟比较高
- hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数
缺点
hive的HQL表达能力有限
(1)迭代式算法无法表达
(2)数据挖掘方面不擅长
hive的效率比较低
(1)hive自动生成的Mapreduce作业,通常情况下不够智能化
(2)hive调优比较困难,粒度较粗(快)
1.3 hive的应用场景
①hive不适合需要低延迟的应用
②hive不是为联机事务处理而设计的,hive不提供实时的查询和基于行级的数据更新操作
③hive的最佳使用场合是大数据集的批处理作业,如网络日志分析
1.4 hive架构及工作原理
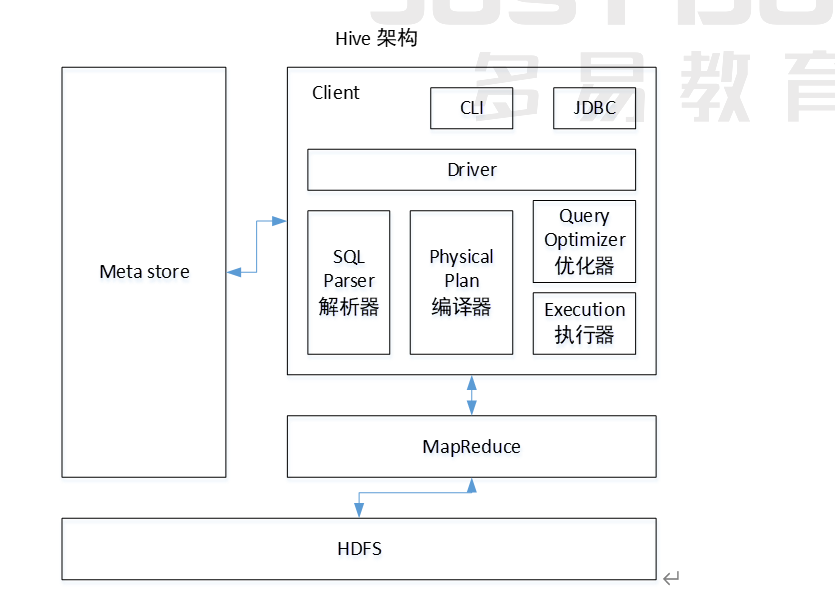
用户接口:Client
CLI(hive shell)、JDBC(java访问hive)、WEB UI(浏览器访问hive)
元数据:Metastore
元数据包括:表名、列名、分区、表属性等信息称为hive元数据
默认存储在内嵌的derby数据库中,推荐使用MySQL存储Metastore。为什么呢?因为derby只能允许一个会话连接,而MySQL支持多用户会话
那为什么不存储在hdfs中呢?因为hive元数据可能面临不断更新、修改和读取,不适合使用hdfs进行存储
Hadoop
使用hdfs进行存储,使用Mapreduce进行计算
驱动器:Driver
- 解析器(SQLParser): 将HQL字符串转换成抽象语法树AST,这一步一般都用第三方工具库完成,比如antlr;对AST进行 语法 分析,比如表是否存在、字段是否存在、SQL语义是否有误
- 编译器(Compiler): 对hql语句进行词法、语法、语义的编译(需要跟元数据关联),编译完成后会生成一个执行计划。 hive上就是编译成mapreduce的job
- 优化器(Optimizer): 将执行计划进行优化,减少不必要的列、使用分区、使用索引等。优化job
- 执行器(Executer): 将优化后的执行计划提交给hadoop的yarn上执行。提交job
hive工作原理
①由hive驱动模块中的编译器对用户输入的HQL语言进行词法和语法解析,将HQL语句转换成抽象语法树AST
②由于抽象语法树的结构仍很复杂,因此,把抽象语法树转化为查询块
③把查询块转换为逻辑查询计划,里面包含了许多逻辑操作符
④重写逻辑查询计划,进行优化,合并多余操作,减少Mapreduce任务数量
⑤将逻辑操作符转换为需要执行的具体的Mapreduce任务
⑥对生成的Mapreduce任务进行优化,生成最终的Mapreduce任务执行计划
⑦由hive驱动模块中的执行器对最终的Mapreduce任务进行执行输出
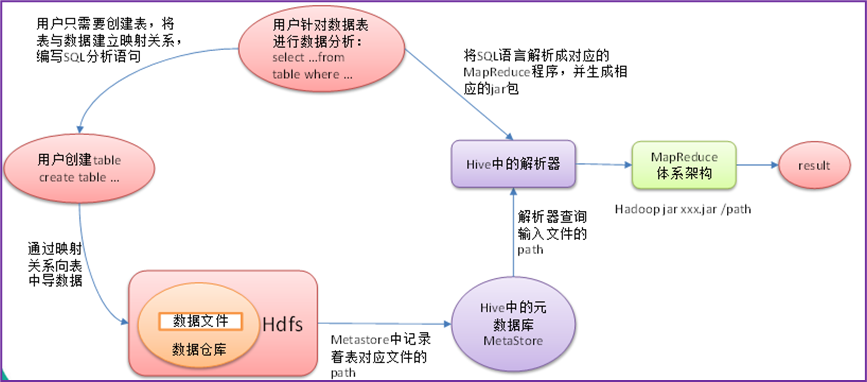
1.5 hive和传统数据库比较
- 数据存储格式不同:hive没有专门的数据存储格式,只需要在创建表时指定数据的列分隔符和行分隔符,hive就可以解析数据;传统数据库的数据存储格式由系统预先定义
- 数据验证不同:hive在数据加载过程中不进行数据验证,而是在数据查询时才进行验证;传统数据库在数据加载时进行验证,因此hive加载数据比传统数据库快
- DML操作不同:hive不支持数据更新操作,支持批量数据导入;传统数据库支持各种DML操作,支持数据更新、单条或批量数据导入
- 延迟性不同:hive操作延迟性高,不适合低延迟操作;传统数据库延迟性低,适合低延迟操作
- 数据规模不同:hive存储在hdfs中,利用Mapreduce进行并行计算,适合大规模数据操作;传统数据库主要采用本地文件系统存储数据,存在容量上限,在本地运行,数据处理能力有限
第2章 hive安装部署
这里附上一篇链接,我就不进行赘述了
[参考文章]: https://blog.csdn.net/W_chuanqi/article/details/130242723 “HIve安装配置(超详细)”
第3章 hive数据类型
3.1 数据类型概述
3.1.1 基本数据类型
TINYINT、SMALLINT、INT、BIGINT、BOOLEAN、FLOAT、DOUBLE、STRING、TIMESTAM-时间类型、BINARY-字节数组
3.1.2 集合数据类型
STRUCT
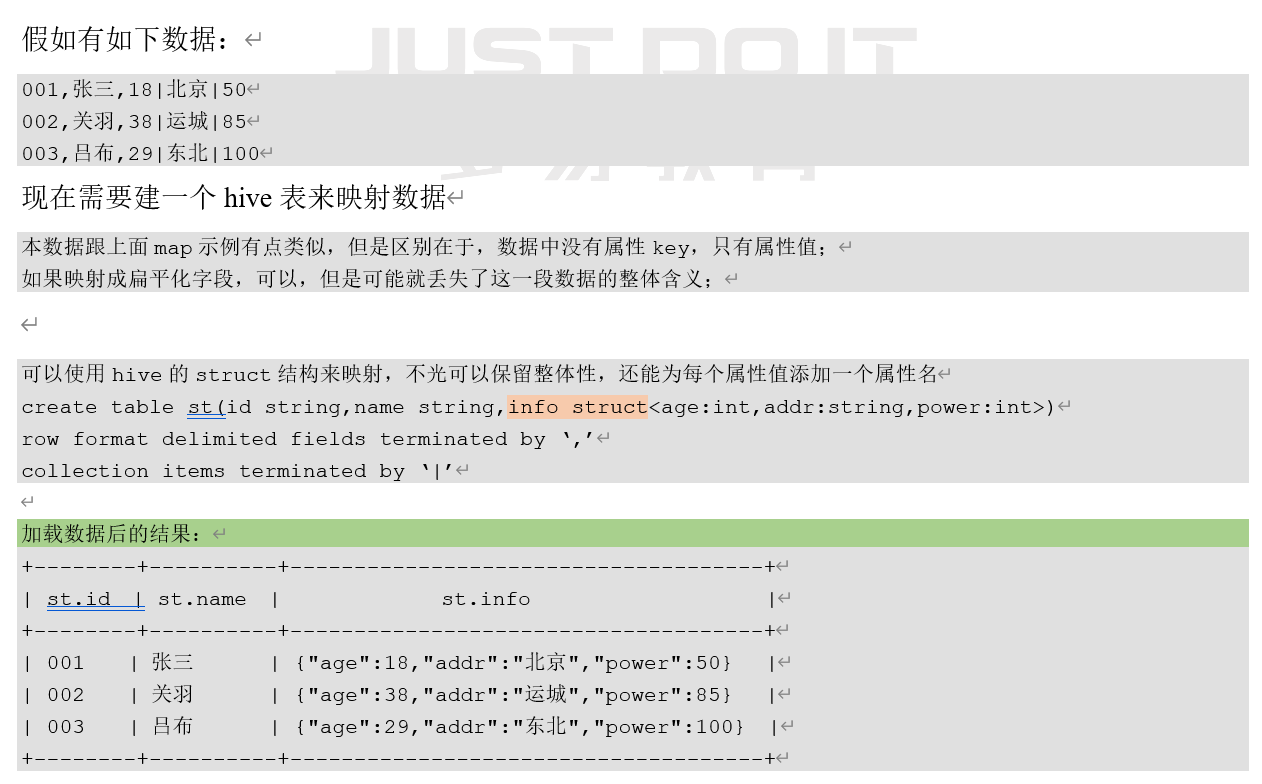
和c语言中的struct类似,都可以通过“点”符号访问元素内容。例如,如果某个列的数据类型是STRUCT{first STRING, last STRING},那么第1个元素可以通过字段’ .first ‘来引用
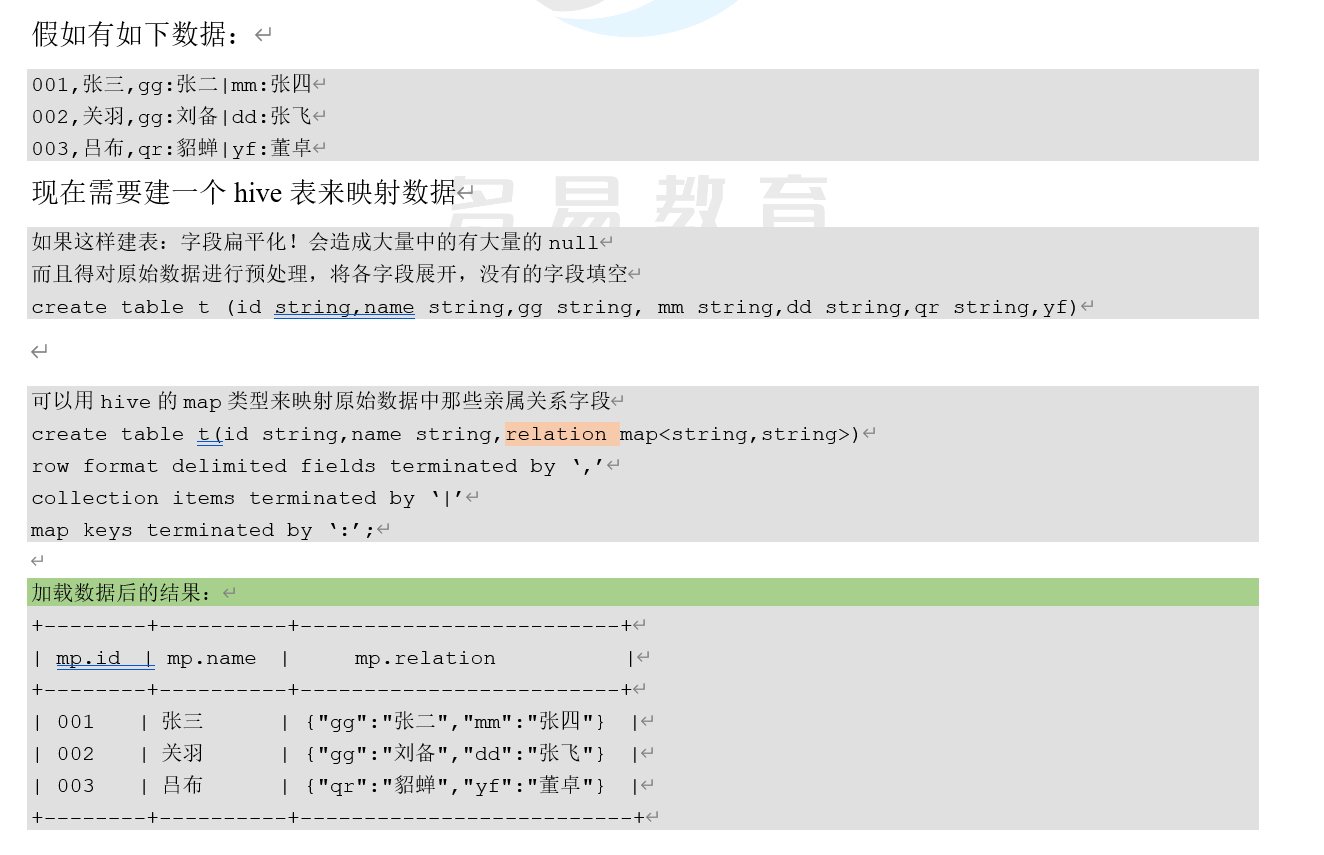
MAP
MAP是一组键-值对元组集合,使用数组标识法可以访问数据。例如,如果某个列的数据类型是MAP,其中键->值对是’ first ‘ ->’ John ‘ 和 ‘ last ‘->’ Doe ‘,那么可以通过字段名[‘ last ‘]获取最后一个元素
ARRAY
数组是一组具有相同类型和名称的变量的集合。这些变量称为数组的元素,每个数组元素都有一个编号,编号从零开始。例如,数组值为[‘ John ‘,’ Doe ‘],那么第2个元素可以通过数组名[1]进行引用
3.2 数据类型详解
3.2.1 数字类型
TINYINT(1字节整数)
SMALLINT (2字节整数)
INT/INTEGER (4字节整数)
BIGINT (8字节整数)
FLOAT (4字节浮点数)
DOUBLE (8字节双精度浮点数)
示例:
create table t_test(a string ,b int,c bigint,d float,e double,f tinyint,g smallint)
3.2.2 时间类型
TIMESTAMP(时间戳)–包含年月日时分毫秒的一种封装
DATE(日期)–只包含年月日
示例,假如有以下数据:
1,zhangsan,1985-06-30
2,lisi,1986-07-10
3,wangwu,1985-08-09
那么,就可以建立一个表来对数据进行映射
create table t_customer(id int, name string, birthday date)
row format delimited fields terminated by ‘,’;
然后导入数据
load data local inpath ‘/root/customer.dat’ into table t_customer;
3.2.3 字符串类型
STRING
VARCHAR(字符串1-65355长度,超长截断)
CHAR (字符串,最大长度255)
3.2.4 其他类型
BOOLEAN(布尔类型):true false
BINARY (二进制数组)
3.2.5 集合类型
3.2.5.1 STRUCT举例
3.2.5.2 MAP举例
3.2.5.3 ARRAY举例
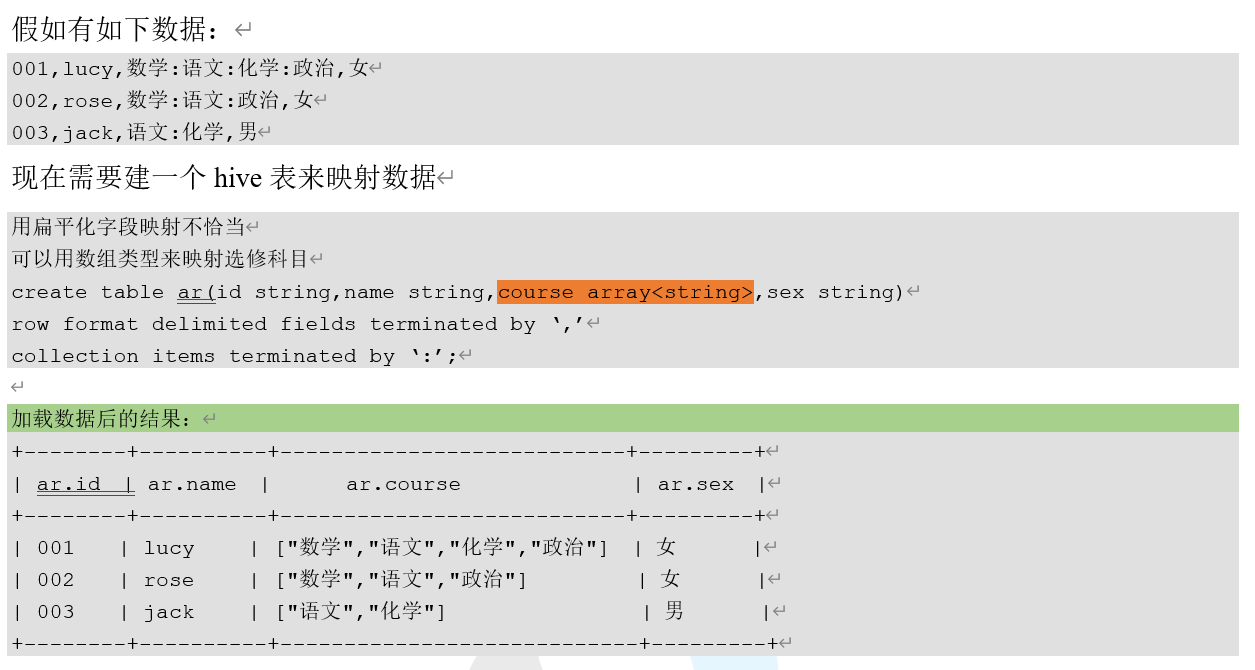
3.3 类型转换
3.3.1 隐式转换
粗粒度–>细粒度
3.3.2 使用CAST操作
例如 CAST(‘1’ AS INT)会把字符串’1’转换成整数1;如果强制类型转换失败,如执行 CAST(‘X’ AS INT),表达式返回空值NULL
第4章 DDL语言
4.1 创建数据库
create database if not exists db_hive location on '在hdfs上的位置';
4.2 查询数据库
//显示数据库
show databases;
//查询通配符匹配的数据库
show databases like 'db_hive*';
//显示数据库详细信息
desc database [extend] db_hive;
4.3 修改数据库
用户可以使用ALTER DATABASE命令为某个数据库的DBPROPERTIES设置键-值对属性值,来描述这个数据库的属性信息,不可以修改数据库元数据信息
alter database db_hive set dbproperties('createtime'='20170830');
4.4 删除数据库
drop databases if exists db_hive;
//如果数据库不为空,可以采用cascade命令,级联删除
drop database db_hive cascade;
4.5 创建表
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name //①EXTERNAL关键字可以让用户创建一个外部表,在建表的同时指定一个指向实际数据的路径(LOCATION),Hive创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径,不对数据的位置做任何改变。在删除表的时候,内部表的元数据和数据会被一起删除,而外部表只删除元数据,不删除数据。
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment] //COMMENT:为表和列添加注释。
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] //PARTITIONED BY创建分区表
[CLUSTERED BY (col_name, col_name, ...)] //CLUSTERED BY创建分桶表
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS] //SORTED BY不常用
[ROW FORMAT row_format] row format delimited fields terminated by “分隔符”
[STORED AS file_format] //STORED AS指定存储文件类型。常用的存储文件类型:SEQUENCEFILE(hadoop_kv序列文件)、TEXTFILE(文本)、RCFILE(列式存储格式文件)、PARQUETFILE(列式存储文件)。如果文件数据是纯文本,可以使用STORED AS TEXTFILE。如果数据需要压缩,使用 STORED AS SEQUENCEFILE。
[LOCATION hdfs_path] //LOCATION :指定表在HDFS上的存储位置。
[LIKE] //LIKE允许用户复制现有的表结构,但是不复制数据.
4.5.1 内部表(也称“管理表”)
在上面代码块中的第①个解释中已说明
4.5.2 外部表
同上
4.5.3 内部表与外部表的互相转换
//查询student1、student2表的类型
desc formatted student1;--内部表
desc formatted student2;--外部表
//修改内部表student1为外部表
alter table student set tblproperties('EXTERNAL'='TRUE');
//修改外部表student2为内部表
alter table student2 set tblproperties('EXTERNAL'='FALSE');
注意:('EXTERNAL'='TRUE')和('EXTERNAL'='FALSE')为固定写法,区分大小写!
4.6 分区表
hive中的分区就是分目录
4.6.1 静态分区
创建静态分区表语法
create table 表名 partition(字段名 字段类型,...) partitioned by(分区字段名 分区字段类型)
row format delimited fields terminated by '\t';
加载数据到分区表中
load data local inpath '本地文件路径' into table 数据库名.表名 partition(分区字段名='分区字段值');
增加分区
alter table 表名 add partition(分区字段名='分区字段值1') partition(分区字段名='分区字段值2') ...;
删除分区
alter table 表名 drop partition(分区字段名='分区字段值1'),partition(分区字段名='分区字段值2'),...;
查看分区表分区
show partitions 表名;
多级分区:partitioned by 多个分区字段
把数据导入分区的三种方式:
(1)方式1:上传数据后修复
(2)方式2:上传数据后添加分区
(3)方式3:创建文件夹后load数据到分区
4.6.2 动态分区
按照某个字段的不同值自动将数据加载到不同分区中
创建动态分区表
create database 表名(字段名 字段类型,...) partitioned by(分区字段名 分区字段类型)
row format delimited fields terminated by '\t';
设置开启动态分区参数
set hive.exec.dynamic.partition=true //使用动态分区
set hive.exec.dynamic.partition.mode=nonstrick;//无限制模式,如果模式是strict,则必须有一个静态分区且放在最前面
set hive.exec.max.dynamic.partitions.pernode=10000;//每个节点生成动态分区的最大个数
set hive.exec.max.dynamic.partitions=100000;//生成动态分区的最大个数
set hive.exec.max.created.files=150000;//一个任务最多可以创建的文件数目
set dfs.datanode.max.xcievers=8192;//限定一次最多打开的文件数
set hive.merge.mapfiles=true; // map端的结果进行合并
set mapreduce.reduce.tasks =20000; //设置reduce task个数 增加reduce阶段的并行度
加载数据
insert into table demo2 partition(x) --此处的分区变量x应该跟demo2中的分区变量名一致
select id, cost, birthday from demo; --select中的最后一个表达式birthday,会作为分区变量x的动态值,注意顺序
4.8 SerDe组件
SerDe是Serialize/Deserilize的简称,目的是用于序列化和反序列化。
用户在建表时可以用自定义的SerDe或使用Hive自带的SerDe,SerDe能为表切分、解析列,且对列指定相应的数据。
创建表
create table 表名(字段名 字段类型,...)
row format serde 'org.apache.hadoop.hive.serde2.RegexSerDe'
with serdeproperties ("input.regex" = "id=(.*),name=(.*)")
stored as textfile;
第5章 数据导入导出操作
5.1 数据导入
5.1.1 使用load向表中装载数据
load data [local] inpath '/opt/module/datas/student.txt' [overwrite] into table student [partition (partcol1=val1,…)];
- load data:表示加载数据
- local:表示从本地加载数据到hive表;否则从HDFS加载数据到hive表
- inpath:表示加载数据的路径
- overwrite:表示覆盖表中已有数据,否则表示追加
- into table:表示加载到哪张表
- student:表示具体的表
- partition:表示上传到指定分区
5.1.2 使用insert…values向表中插入数据
insert into table student1 partition(month='201709') values(1,'wangwu');
5.1.3 使用insert…select向表中插入数据
insert overwrite table student2 partition(month='201708') select id, name from student1 where month='201709';
5.1.4 用create as创建表并加载数据
create table if not exists student3
as
select id, name from student;
5.1.5 创建表时通过指定location加载数据路径
create table if not exists student4(id int, name string) row format delimited fields terminated by '\t' location '/user/hive/warehouse/student4';
5.1.6 import数据到指定Hive表中
import table student2 partition(month='201709') from '/user/hive/warehouse/export/student';
注意:先用export导出后,再将数据导入
5.2 数据导出
5.2.1 insert导出
insert overwrite [local] directory '/opt/module/datas/export/student1'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
select * from student;
5.2.2 export导出到HDFS上
export table default.student to '/user/hive/warehouse/export/student';
5.3 清除表中数据(Truncate)
truncate table student;
注意:Truncate只能删除管理表(内部表),不能删除外部表中数据
- 标题: 关于数据仓库hive知识的学习(1)
- 作者: 宣胤
- 创建于: 2023-04-27 16:24:33
- 更新于: 2023-05-20 23:00:48
- 链接: http://xuanyin02.github.io/2023/042713923.html
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。