

关于实时计算框架flink知识的学习(1)
这一篇文章我要分享的是flink实时计算框架,我先解释一下flink的基本概念:一个分布式的、有状态的实时流式处理系统(编程框架)。那么就会有人问:之前不是学习过spark streaming吗,也能做实时流式处理,为什么还要学习flink?其实答案很简单:flink比spark streaming更实时!spark streaming的流式处理是基于微批处理的思想,需要隔一点时间才会去处理,flink采用了基于操作符的连续模型,可以做到微秒级别的延迟
下面就是我分享的知识:
1 快速认识flink
1.1 flink基本概念
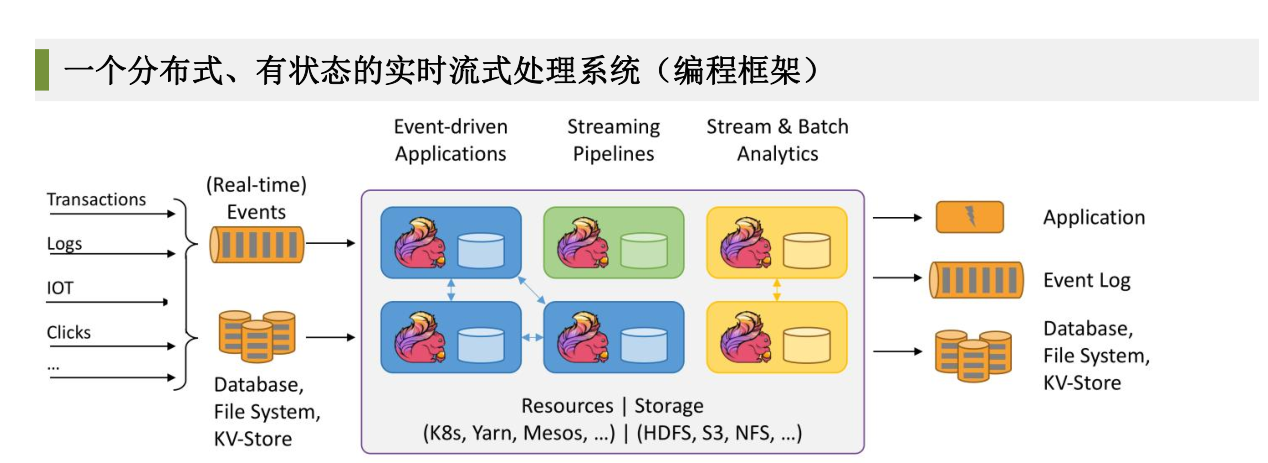
flink,以流处理方式作为基础的世界观,并通过引入有界流来实现批计算,从而实现流批一体,可以说是非常np
1.2 flink的运行架构
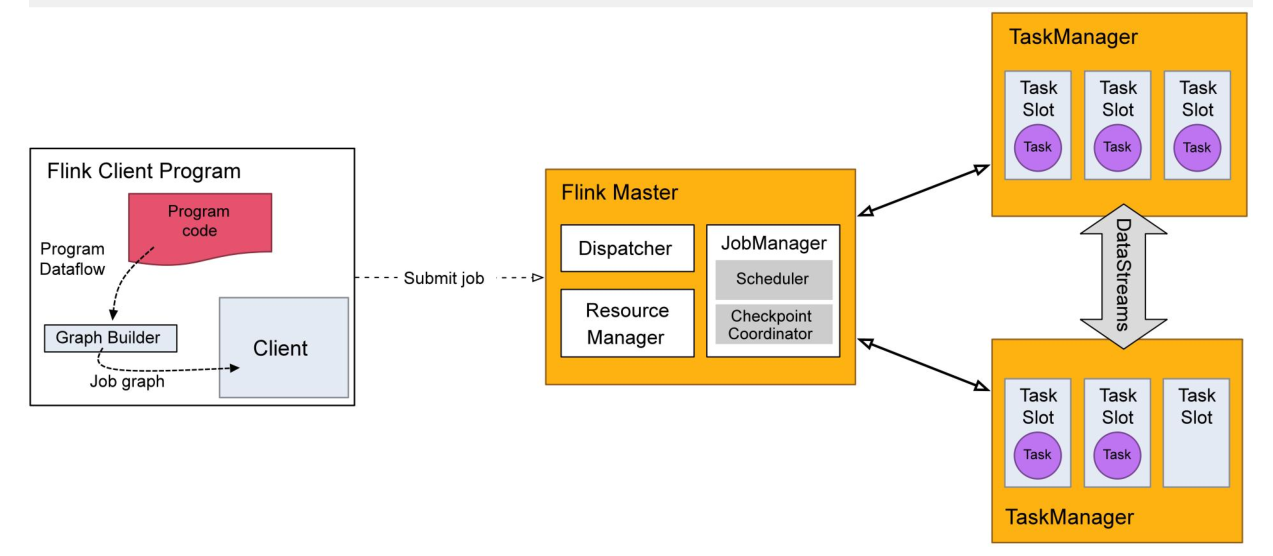
flink集群采用 Master - Slave 架构:
- Master的角色为JobManager,负责集群和作业管理
- Slave的角色是TaskManager,负责执行计算任务
- 客户端Client负责集群和提交任务,JobManager 和 TaskManager是集群的进程
各角色主要职责说明:
- Client:是flink提供的CLI命令行工具,用来提交flink作业到flink集群,在客户端中负责 Stream Graph(流图)和 Job Graph(作业图)的构建
- JobManager:根据并行度将flink客户端提交的flink应用分解为子任务,从资源管理器ResourceManager申请所需的计算资源,资源具备之后,开始分发到TaskManager执行Task,并负责应用容错,跟踪作业的执行状态,发现异常则恢复作业等
- TaskManager:接收JobManager分发的子任务,根据自身的资源情况,管理子任务的启动、停止、销毁、异常恢复等生命周期阶段。flink程序中必须有一个TaskManager
1.3 flink的特性
适用于几乎所有的流式数据处理管道
- 事件驱动型应用
- 流、批数据分析
- 数据管道及ETL
自带状态管理机制

image-20230505172208248 强大的准确性保证
- exactly-once 状态一致性
- 事件时间处理
- 专业的迟到数据处理
灵活丰富的多层api
- 流、批数据之上的SQL查询
- 流、批数据之上的TableApi
- datastream流处理算子api、dataset批处理算子api
- 精细可控的processFunction
规模弹性扩展
- 可扩展的分布式架构(集群级别的资源规模灵活配置,算子粒度的独立并行度灵活配置)
- 支持超大状态管理
- 增量checkpoint机制
强大的运维能力
- 弹性实施部署机制
- 高可用机制
- 保存点恢复机制
优秀的性能
- 低延迟
- 高吞吐
- 内存计算
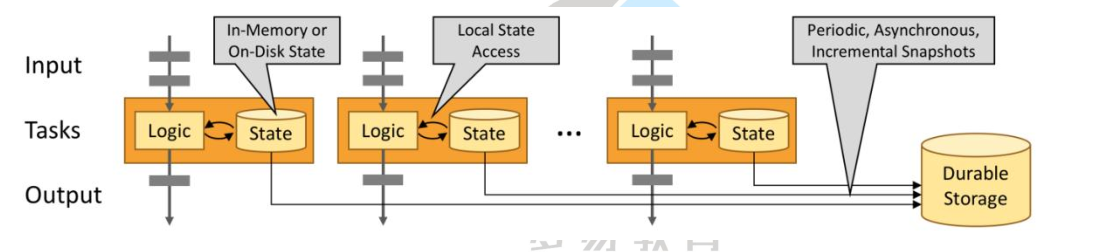
2 flink编程基础
2.1 flink的DataStream抽象
- DataStream 代表一个数据流,它可以是无界的,也可以是有界的
- DataStream 类似于Spark的rdd,它是不可变的
- 无法对一个DataStream进行自由的添加或删除或修改元素
- 只能通过算子对DataStream中的数据进行转换,将一个DataStream转成另一个DataStream
- DataStream可以通过source算子加载、映射外部数据而来;或者从已存在的DataStream转换而来
2.2 flink编程模板
- 获取一个编程、执行入口环境env
- 通过数据源组件、加载、创建DataStream
- 对DataStream调用各种处理算子表达计算逻辑
- 通过sink算子指定计算结果的输出方式
- 在env上触发程序提交运行
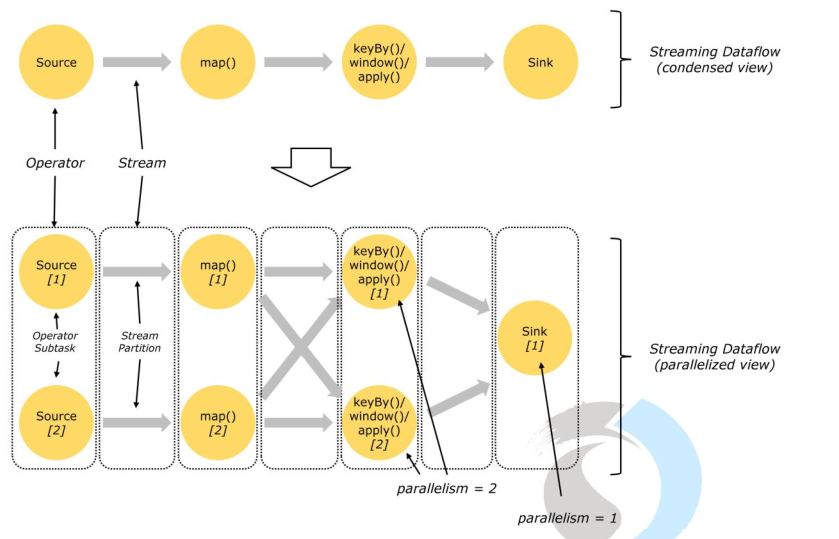
2.3 flink程序的并行概念
flink程序中,每一个算子都可以成为一个独立任务(task)
flink程序中,视上下游算子间数据分发规划、并行度、共享槽位设置,可组成算子链成为一个task
每个任务在运行时都可拥有多个并行是运行实例(subtask)
且每个算子任务的并行度都可以在代码中显式设置
image-20230514180529758
2.4 flink编程入口
批处理入口
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnviroment();
流处理入口
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnviroment();
流批一体处理入口
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnviroment();
//为env设置环境参数
ExecutionConfig config = env.getConfig();
//设置为批处理模式
config.setExecutionMode(ExecutionMode.BATCH);
开启webui的本地运行环境处理入口
Configuration conf = new Configuration();
conf.setInteger("rest.port",8081);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnviroment(conf);
要开启上述webui功能,需添加依赖:flink-runtime-web_2.12
2.5 基本source算子
source是用来获取外部数据的算子,按照获取数据的方式,可以分为:
- 基于集合的Source
- 基于Socket网络端口的Source
- 基于文件的Source
- 第三方Connector Source
- 自定义Source
在此我仅介绍 第三方Connector Source 和 自定义Source
在实际生产环境中,为了保证flink可以高效读取数据源中的数据,通常是跟一些分布式消息中间件结合使用,例如Kafka。Flink和Kafka整合可以高效的读取数据,并且可以保证Exactly Once(精确一次性语义)
第三方Connector Source
以 Kafka Source为例:首先引入依赖:flink-connector-kafka_2.12
示例代码:
KafkaSource<String> kafkaSource = KafkaSource.<String>builder()
.setTopics("first") //设置主题
.setGroupId("01") //设置消费组ID
.setBootstrapServers("node1:9092") //设置kafka连接地址
//OffsetsInitializer.committedOffsets(OffsetResetStrategy.LATEST) 消费起始位移选择之前提交的偏移量(如果没有,则重置为LATEST)
//OffsetsInitializer.earliest() 消费起始位移直接选择为“最早”
//OffsetsInitializer.latest() 消费起始位移直接选择为“最新”
//OffsetsInitializer.offsets(Map< TopicPartition,Long>) 消费起始位移为:方法所传入的每个分区和对应的起始偏移量
.setStartingOffsets(OffsetsInitializer.committedOffsets(OffsetResetStrategy.LATEST))
.setValueOnlyDeserializer(new SimpleStringSchema()) //设置反序列化Schema,SimpleStringSchema指的是读取kafka中的数据反序列化成String格式
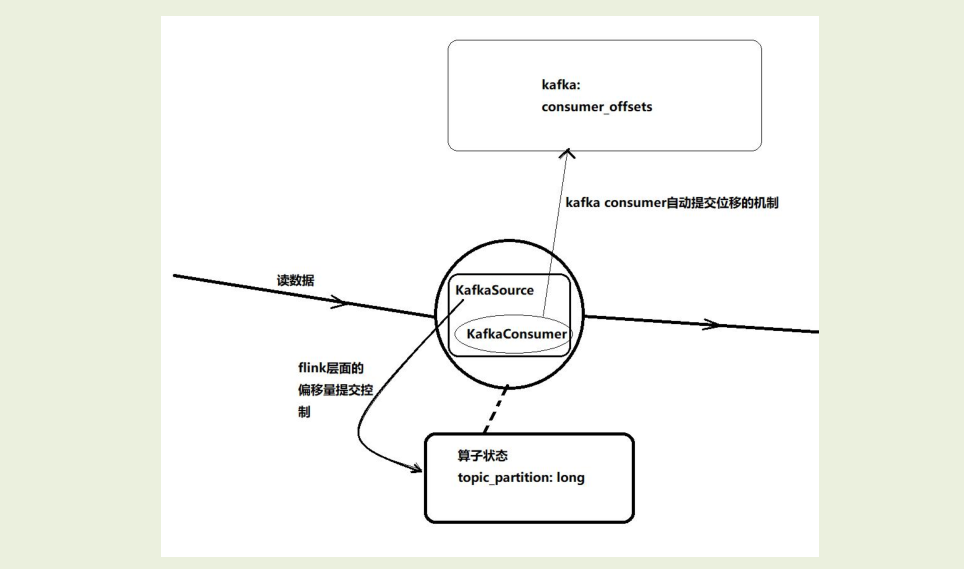
//开启了Kafka底层消费者的自动位移提交机制,它会把最新的消费位移提交到Kafka的consumer_offsets中
//但是就算把自动位移提交机制开启,KafkaSource依然不依赖自动提交机制(宕机重启时,优先从flink算子自己的状态去获取偏移量<更可靠>)
.setProperty("auto.offset.commit", "true")
//把本source算子设置成 BOUNDED(有界流),将来本source去读取数据的时候,读到指定的位置,就停止读取并退出
//常用来补数或者重跑一段历史数据
//.setBounded(OffsetsInitializer.committedOffsets());
//把本source算子设置成 UNBOUNDED(无界流),但是并不会一直读取数据,而是达到指定位置就停止读取,但程序不退出
//主要应用场景: 需要从Kafka中读取某一段固定长度的数据,然后拿着这段数据去跟真正的无界流联合处理
//.setUnbounded(OffsetsInitializer.latest())
.build();
flink会把kafka消费者的消费位移记录在算子状态中,这样就实现了消费位移状态的容错,从而可以支持端到端的exactly-once
自定义Source
本质上就是定义一个类,实现SourceFunction或继承RichParallelSourceFunction,实现run方法和cancel方法
示例代码:
public class MyParallelSource extends RichParallelSourceFunction<String> {
private int i = 1; //定义一个 int 类型的变量,从 1 开始
private boolean flag = true; //定义一个 flag 标标志
//run 方法就是用来读取外部的数据或产生数据的逻辑
@Override
public void run(SourceContext<String> ctx) throws Exception {
//满足 while 循环的条件,就将数据通过 SourceContext 收集起来
while (i <= 10 && flag) {
Thread.sleep(1000); //为避免太快,睡眠 1 秒
ctx.collect("data:" + i++); //将数据通过 SourceContext 收集起来
}
}
//cancel 方法就是让 Source 停止
@Override
public void cancel() {
//将 flag 设置成 false,即停止 Source
flag = false;
}
}
2.6 基本transformation算子
2.6.1 映射算子
- map映射:DataStream.map( new MapFunction(…){})
- flatMap扁平化映射:DataStream.flatMap( new FlatMapFunction(…){})
如果是调用flatMap方法时传入Lambda表达式,需要在调用flatMap方法后,在调用returns方法指定返回的数据的类型。不然Flink无法自动推断出返回的数据类型,会出现异常。
比如返回一个元组:
return Types.TUPLE(Types.String,Types.INT)
- project 投影:DataStream.project(元组索引)
该算子只能对Tuple类型数据使用,project方法的功能类似sql中的”select”字段;该方法只有Java的API有,Scala的API没有此方法。
例如:DataStream.project(0,2)
2.6.2 过滤算子
filter过滤:DataStream.filter( new FilterFunction(…){})
2.6.3 分组算子
keyBy按key分组:DataStream.keyBy()
//按照 Tuple2 中的第 0 个位置进行分组,分组后得到 KeyedStream
KeyedStream<Tuple2<String, Integer>, Tuple> keyed = wordAndOne.keyBy(0);
//按照 Bean 中的属性名 word 进行分组
KeyedStream<CountBean, Tuple> keyed = wordAndOne.keyBy("word");
2.6.4 滚动聚合算子
此处所说的滚动聚合算子,是多个聚合算子的统称,有sum、min、minBy、max、maxBy;
这些算子的底层逻辑都是维护一个聚合值,并使用每条流入的数据对聚合值进行滚动更新; 这些算子都只能在KeyedStream上调用(就是必须keyBy之后调用)。
- sum:该算子实现实时滚动相加的功能,即新输入的数据和历史数据进行相加
- min、minBy:这两个算子都是求最小值
min和minBy的区别在于:
min的返回值,最小值字段以外,其他字段是第一条输入数据的值;
minBy的返回值,就是最小值字段所在的那条数据。 - max、maxBy同理
- reduce规约:它的滚动聚合逻辑没有写死,而是由用户通过ReduceFunction来传入
- fold折叠:1.12版本已移除
2.7 基本sink算子
sink算子是将计算结果最终输出的算子;不同的sink算子可以将数据输出到不同的目标,如写入到文件、输出到指定的网络端口、消息中间件、外部的文件系统或者是打印到控制台。
2.7.1 打印输出(略)
2.7.2 文件sink
- 第一种方法:result.wirteAs[x] (存储路径)–x可以是Text、Csv。但是此种方法已被移除
- 第二种方法:result.writeUsingOutputFormat( new TextOutputFormat<>(new Path( path ))) 以指定的格式输出
- 第三种方法:result.writeToSocket( ip地址, 端口号, new SimpleStrignSchema()) 输出到网络端口
2.8 扩展sink算子
2.8.1 StreamFileSink
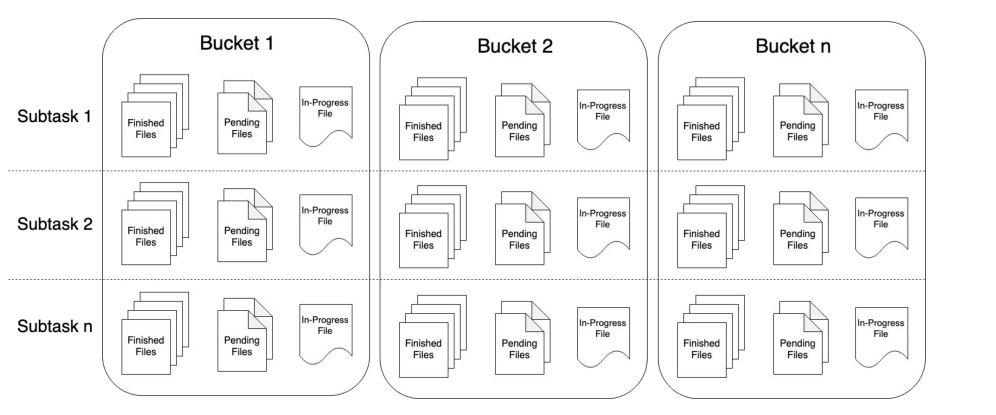
该Sink不但可以将数据写入到各种文件系统,而且整合了checkpoint机制来保证Exactly Once语义,还可以对文件进行分桶存储,还支持以列式存储的格式写入,功能更强大。
StreamFileSink中输出的文件,其生命周期会经历3种状态:
in-progress Files
Pending Files
Finshed Files
image-20230525120857757
代码模块要点:通过DefaultRollingPolicy这个工具类,指定文件滚动生成的策略。这里设置的文件滚动生成策略有两个,一个是距离上一次生成文件时间超过30秒,另一个是文件大小达到100mb。这两个条件只要满足其中一个即可滚动生成文件。然后StreamingFileSink.forRowFormat方法将文件输出目录、文件写入的编码传入。再调用withRollingPolicy关联上面的文件滚动生成策略,接着调用build方法构建好StreamingFileSink,最后将其作为参数传入到addSink方法中。
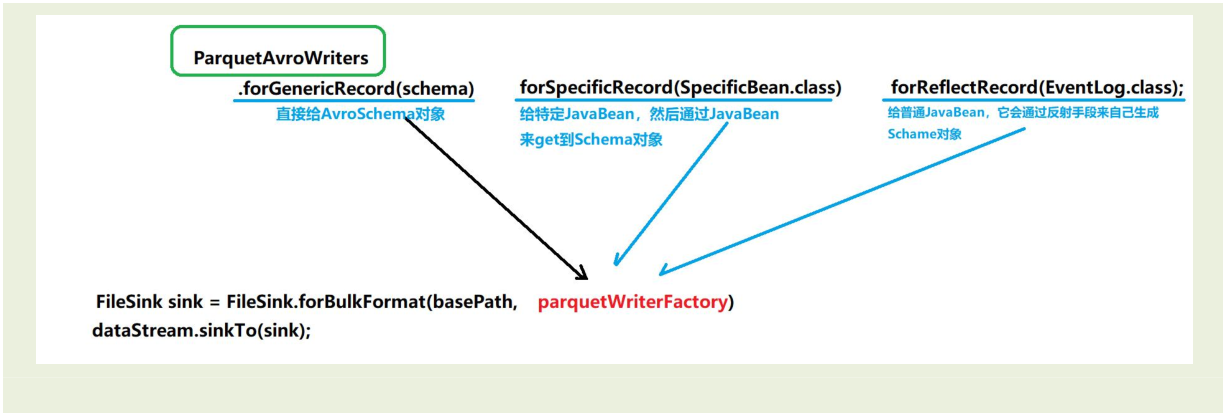
列式存储文件输出代码结构剖析
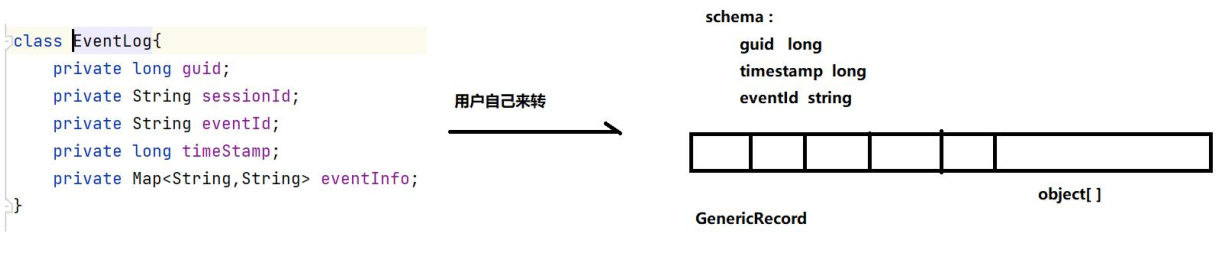
GenericRecord 与 Schema 的关系
2.8.1.1 Row格式文件输出代码案例
DataStream<String> dataSteam = …
//构建文件滚动生成的策略
DefaultRollingPolicy<String, String> rollingPolicy = DefaultRollingPolicy.create()
.withRolloverInterval(30 * 1000L) //30 秒滚动生成一个文件
.withMaxPartSize(1024L * 1024L * 100L) //当文件达到 100m 滚动生成一个文件
.build();
//创建 StreamingFileSink,数据以行格式写入
StreamingFileSink<String> sink = StreamingFileSink.forRowFormat(
new Path(outputPath), //指的文件存储目录
new SimpleStringEncoder<String>("UTF-8")) //指的文件的编码
.withRollingPolicy(rollingPolicy) //传入文件滚动生成策略
.build();
//调用 DataStream 的 addSink 添加该 Sink
dataSteam.addSink(sink);
2.8.1.2 Bulk列式存储文件输出代码实例1
手动构建Avro的Schema对象,得到ParquetWriterFactory的方式
/**
* 方式一:
* 核心逻辑:
* - 构造一个 schema
* - 利用 schema 构造一个 parquetWriterFactory
* - 利用 parquetWriterFactory 构造一个 FileSink 算子
* - 将原始数据转成 GenericRecord 流,输出到 FileSink 算子
*/
// 1. 先定义 GenericRecord 的数据模式
Schema schema = SchemaBuilder.builder()
.record("DataRecord")
.namespace("cn.doitedu.flink.avro.schema")
.doc("用户行为事件数据模式")
.fields()
.requiredInt("gid")
.requiredLong("ts")
.requiredString("eventId")
.requiredString("sessionId")
.name("eventInfo")
.type()
.map()
.values()
.type("string")
.noDefault()
.endRecord();
// 2. 通过定义好的 schema 模式,来得到一个 parquetWriter
ParquetWriterFactory<GenericRecord> writerFactory = ParquetAvroWriters.forGenericRecord(schema);
// 3. 利用生成好的 parquetWriter,来构造一个 支持列式输出 parquet 文件的 sink 算子
FileSink<GenericRecord> bulksink = FileSink.forBulkFormat(new Path("d:/datasink/"), writerFactory)
.withBucketAssigner(new DateTimeBucketAssigner<GenericRecord>("yyyy-MM-dd--HH"))
.withRollingPolicy(OnCheckpointRollingPolicy.build())
.withOutputFileConfig(OutputFileConfig.builder().withPartPrefix("doit_edu").withPartSuffix(".parquet" ).build())
.build();
// 4. 将自定义 javabean 的流,转成 上述 sink 算子中 parquetWriter 所需要的 GenericRecord 流
SingleOutputStreamOperator<GenericRecord> recordStream = streamSource
.map((MapFunction<EventLog, GenericRecord>) eventLog -> {
// 构造一个 Record 对象
GenericData.Record record = new GenericData.Record(schema);
// 将数据填入 record
record.put("gid", (int) eventLog.getGuid());
record.put("eventId", eventLog.getEventId());
record.put("ts", eventLog.getTimeStamp());
record.put("sessionId", eventLog.getSessionId());
record.put("eventInfo", eventLog.getEventInfo());
return record;
}).returns(new GenericRecordAvroTypeInfo(schema)); // 由于 avro 的相关类、对象需要用 avro
的序列化器,所以需要显式指定 AvroTypeInfo 来提供 AvroSerializer
// 5. 输出数据
recordStream.sinkTo(bulksink);
2.8.1.3 Bulk列式存储文件输出代码实例2
编写 avsc 配置文件,并利用插件生成“特定 JavaBean”,得到 ParquetWriterFactory 的方式
avsc配置文件:得到“特定 JavaBean”–AvroEventLogBean
{"namespace": "cn.doitedu.flink.avro.schema",
"type": "record",
"name": "AvroEventLog",
"fields": [
{"name": "guid", "type": "long"},
{"name": "sessionId", "type": "string"},
{"name": "eventId", "type": "string"},
{"name": "timeStamp", "type": "long"},
{"name": "eventInfo", "type": { "type":"map","values": "string"} }
]
}
/**
* 方式二:
* 核心逻辑:
* - 编写一个 avsc 文本文件(json),来描述数据模式
* - 添加 maven 代码生成器插件,来针对上述的 avsc 生成 avro 特定格式的 JavaBean 类
* - 利用代码生成器生成的 JavaBean,来构造一个 parquetWriterFactory
* - 利用 parquetWriterFactory 构造一个 FileSink 算子
* - 将原始数据流 转成 特定格式 JavaBean 流,输出到 FileSink 算子
*/
// 1. 先定义avsc文件放在resources文件夹中,并用maven的插件,编译一下,生成特定格式的JavaBean :AvroEventLog
// 这种根据 avsc 生成的 JavaBean 类,自身就已经带有了 Schema 对象
// AvroEventLog avroEventLog = new AvroEventLog();
// Schema schema = avroEventLog.getSchema();
// 2. 通过自动生成 AvroEventLog 类,来得到一个 parquetWriter
ParquetWriterFactory<AvroEventLog> parquetWriterFactory =
ParquetAvroWriters.forSpecificRecord(AvroEventLog.class);
// 3. 利用生成好的 parquetWriter,来构造一个 支持列式输出 parquet 文件的 sink 算子
FileSink<AvroEventLog> bulkSink = FileSink.forBulkFormat(new Path("d:/datasink2/"),
parquetWriterFactory)
.withBucketAssigner(new DateTimeBucketAssigner<AvroEventLog>("yyyy-MM-dd--HH"))
.withRollingPolicy(OnCheckpointRollingPolicy.build()) .withOutputFileConfig(OutputFileConfig.builder().withPartPrefix("doit_edu").withPartSuffix(".parquet" ).build())
.build();
// 4. 将自定义 javabean 的 EventLog 流,转成 上述 sink 算子中 parquetWriter 所需要的 AvroEventLog 流
SingleOutputStreamOperator<AvroEventLog> avroEventLogStream = streamSource.map(new
MapFunction<EventLog, AvroEventLog>() {
@Override
public AvroEventLog map(EventLog eventLog) throws Exception {
HashMap<CharSequence, CharSequence> eventInfo1 = new HashMap<>();
// 进行 hashmap<charsequenct,charsequence>类型的数据转移
Map<String, String> eventInfo2 = eventLog.getEventInfo();
Set<Map.Entry<String, String>> entries = eventInfo2.entrySet();
for (Map.Entry<String, String> entry : entries) {
eventInfo1.put(entry.getKey(), entry.getValue());
}
return new AvroEventLog(eventLog.getGuid(), eventLog.getSessionId(),
eventLog.getEventId(), eventLog.getTimeStamp(), eventInfo1);
}
});
// 5. 输出数据
avroEventLogStream.sinkTo(bulkSink);
2.8.1.4 Bulk列式存储文件输出代码实例3
直接利用普通JavaBean,利用工具本身的反射机制,得到ParquetWriterFactory的方式
/**
* 方式三:
* 核心逻辑:
* - 利用自己的 JavaBean 类,来构造一个 parquetWriterFactory
* - 利用 parquetWriterFactory 构造一个 FileSink 算子
* - 将原始数据流,输出到 FileSink 算子
*/
// 1. 通过自己的 JavaBean 类,来得到一个 parquetWriter
ParquetWriterFactory<EventLog> parquetWriterFactory = ParquetAvroWriters.forReflectRecord(EventLog.class);
// 2. 利用生成好的 parquetWriter,来构造一个 支持列式输出 parquet 文件的 sink 算子
FileSink<EventLog> bulkSink = FileSink.forBulkFormat(new Path("d:/datasink3/"),parquetWriterFactory)
.withBucketAssigner(new DateTimeBucketAssigner<EventLog>("yyyy-MM-dd--HH"))
.withRollingPolicy(OnCheckpointRollingPolicy.build())
.withOutputFileConfig(OutputFileConfig.builder().withPartPrefix("doit_edu").withPartSuffix(".parquet" ).build())
.build();
// 3. 输出数据
streamSource.sinkTo(bulkSink);
2.8.2 KafkaSink
核心类
- KafkaStringSerializationSchema – 反序列化
- FlinkKafkaProducer – 生产者(即sink)
示例代码:
// 读数据,写入 kafka
DataStreamSource<String> source = env.socketTextStream("localhost", 9099);
KafkaSink<String> kafkaSink = KafkaSink.<String>builder()
.setBootstrapServers("doit01:9092,doit02:9092,doit03:9092")
.setRecordSerializer(
KafkaRecordSerializationSchema.builder()
.setTopic("topic-name")
.setValueSerializationSchema(new SimpleStringSchema())
.build()
)
.setDeliverGuarantee(DeliveryGuarantee.AT_LEAST_ONCE)
.setTransactionalIdPrefix("doitedu-")
.build();
source.sinkTo(kafkaSink);
KafkaSink是能结合Flink的Checkpoint机制,来支持端到端精确一次语义的(底层是利用了kafka producer的事务机制)
2.8.3 JdbcSink
JdbcSink也是能支持端到端精确一次语义的
示例代码:
SinkFunction<Student> exactlyOnceSink = JdbcSink.exactlyOnceSink(
"insert into flink_stu values (?,?,?,?) on duplicate key update name=?,gender=?,score=? ",
(PreparedStatement preparedStatement, Student student) -> {
preparedStatement.setInt(1, student.getId());
preparedStatement.setString(2, student.getName());
preparedStatement.setString(3, student.getGender());
preparedStatement.setFloat(4, (float) student.getScore());
preparedStatement.setString(5, student.getName());
preparedStatement.setString(6, student.getGender());
preparedStatement.setFloat(7, (float) student.getScore());
},
JdbcExecutionOptions.builder()
.withMaxRetries(3)
.withBatchSize(1)
.build(),
JdbcExactlyOnceOptions.builder()
// mysql 不支持同一个连接上存在并行的多个事务,必须把该参数设置为 true
.withTransactionPerConnection(true)
.build(),
new SerializableSupplier<XADataSource>() {
@Override
public XADataSource get() {
// XADataSource 就是 jdbc 连接,不过它是支持分布式事务的连接
// 而且它的构造方法,不同的数据库构造方法不同
MysqlXADataSource xaDataSource = new MysqlXADataSource();
xaDataSource.setUrl("jdbc:mysql://doit01:3306/abc");
xaDataSource.setUser("root");
xaDataSource.setPassword("ABC123.abc123");
return xaDataSource;
}
}
);
// 把构造好的 sink 添加到流中
studentStream.addSink(exactlyOnceSink);
2.8.4 RedisSink
Redis是一个基于内存、性能极高的NoSQL数据库,数据还可以持久化到磁盘,读写速度快,适合存储key-value类型的数据。Redis不仅仅支持简单的key-value类型的数据,同时还提供list、set、zset、hash等数据结构的存储。Flink实时计算出的结果,需要快速的输出存储起来,要求写入的存储系统的速度要快,这个才不会造成数据积压。Redis就是一个非常不错的选择。
使用实例
首先在maven中导入依赖:flink-connector-redis_2.12
接下来就是定义一个类(或者静态内部类)实现RedisMapper接口,需要指定一个泛型,即写入到Redis的数据的类型,并实现三个方法:
- getCommandDescription 方法,返回 RedisCommandDescription 实例,在该构造方法中可以指定写入到 Redis 的方法类型为 HSET,和 Redis 的 additionalKey 即 value 为 HASH 类型外面 key 的值的名称;
- getKeyFromData 是指定 value 为 HASH 类型对应 key 的值;
- geVauleFromData 是指定 value 为 HASH 类型对应 value 的值。
public static class RedisWordCountMapper implements RedisMapper<Tuple2<String, Integer>> {
@Override
public RedisCommandDescription getCommandDescription() {
//写入 Redis 的方法,value 使用 HASH 类型,并指定外面 key 的值的名称
return new RedisCommandDescription(RedisCommand.HSET, "WORD_COUNT");
}
@Override
public String getKeyFromData(Tuple2<String, Integer> data) {
return data.f0; //指定写入 Redis 的 value 里面 key 的值
}
@Override
public String getValueFromData(Tuple2<String, Integer> data) {
return data.f1.toString(); //指定写入 value 里面 value 的值
}
}
在使用之前,先 new FlinkJedisPoolConfig,设置 Redis 的 ip 地址或主机名、端口号、密码等。然后 new RedisSink 将准备好的 conf 和 RedisWordCountMapper 实例传入到其构造方法中,最后调用 DataStream的 addSink 方法,将 new 好的 RedisSink 作为参数传入。
DataStream<Tuple2<String, Integer>> result = wordAndOne.keyBy(0).sum(1);
//设置 Redis 的参数,如地址、端口号等
FlinkJedisPoolConfig conf = new
FlinkJedisPoolConfig.Builder().setHost("localhost").setPassword("123456").build();
//将数据写入 Redis
result.addSink(new RedisSink<>(conf, new RedisWordCountMapper()));
3 flink多流操作API
3.1 split分流 [已deprecated]
3.2 侧流输出
首先定义侧流标签,比如:maleOutputTag、femaleOutputTag
侧流输出示例代码:
SingleOutputStreamOperator<Student> mainStream = students.process(new ProcessFunction<Student, Student>()
{
@Override
public void processElement(Student student, ProcessFunction<Student, Student>.Context ctx,
Collector<Student> collector) throws Exception {
if (student.getGender().equals("m")) {
// 输出到测流“maleOutputTag”
ctx.output(maleOutputTag, student);
} else if (student.getGender().equals("f")) {
// 输出到测流“femaleOutputTag”
ctx.output(femaleOutputTag, student.toString());
} else {
// 在主流中输出
collector.collect(student);
}
}
});
//获取侧流输出结果
SingleOutputStreamOperator<Student> side1 = mainStream.getSideOutput(maleOutputTag);
SingleOutputStreamOperator<String> side2 = mainStream.getSideOutput(femaleOutputTag);
以下 function 函数,支持将特定数据输出到侧流中:
- ProcessFunction
- KeyedProcessFunction
- CoProcessFunction
- KeyedCoProcessFunction
- ProcessWindowFunction
- ProcessAllWindowFunction
3.3 connect连接操作
该方法可以将两个任意类型的的DataStream连接成一个新的ConnectedStreams。需要注意的是,connect方法与union方法不同,连接形成的ConnectedStreams里面的两个流依然是相互独立的。connect方法最大的好处是可以让两个流共享State状态。
示例代码:
//将两个 DataStream 连接到一起
ConnectedStreams<String, Integer> connected = DataStream1.connect(DataStream2);
接下来讲讲对ConnectedStreams的操作方法
coMap:对 ConnectedStreams 调用map方法时需要传入CoMapFunction
该接口需要指定 3 个泛型:
- 第一个输入 DataStream 的数据类型
- 第二个输入 DataStream 的数据类型
- 返回结果的数据类型
该接口需要重写两个方法(这两个方法必须是相同的返回值类型):
- map1 方法,是对第 1 个流进行 map 的处理逻辑
- map2 方法,是对 2 个流进行 map 的处理逻辑
示例代码:
//对 ConnectedStreams 中两个流分别调用个不同逻辑的 map 方法
DataStream<String> result = wordAndNum.map(new CoMapFunction<String, Integer, String>() {
@Override
public String map1(String value) throws Exception {
return value.toUpperCase(); //第一个 map 方法是将第一个流的字符变大写
}
@Override
public String map2(Integer value) throws Exception {
return String.valueOf(value * 10); //第二个 map 方将是第二个流的数字乘以 10 并转成 String
}
});
coFlatMap:对 ConnectedStreams 调用flatMap方法需要传入CoFlatMapFunction
该接口需要重写两个方法(这两个方法必须是相同的返回值类型):
- flatMap1 方法,是对第 1 个流进行 flatMap 的处理逻辑
- flatMap2 方法,是对 2 个流进行 flatMap 的处理逻辑
示例代码:
//对 ConnectedStreams 中两个流分别调用个不同逻辑的 flatMap 方法
DataStream<String> result = connected.flatMap(new CoFlatMapFunction<String, String, String>() {
@Override
public void flatMap1(String value, Collector<String> out) throws Exception {
String[] words = value.split(" ");
for (String w : words) {
out.collect(w);
}
}
@Override
public void flatMap2(String value, Collector<String> out) throws Exception {
String[] nums = value.split(",");
for (String n : nums) {
out.collect(n);
}
}
});
3.4 union合并操作
该方法可以将两个或者多个数据类型一致的DataStream合并成一个DataStream。
示例代码:
//将两个 DataStream 合并到一起
DataStream result = odd.union(even);
3.5 coGroup协同分组
coGroup本质上是join算子的底层算子,功能类似(略)
3.6 join关联操作
用于关联两个流(类似于sql中的join),需要指定join条件;需要在窗口中进行关联后的逻辑计算
join算子的代码结构:
stream.join(otherStream)
.where(<KeySelector>)
.equalTo(<KeySelector>)
.window(<WindowAssigner>)
.apply(<JoinFunction>)
那我们先介绍一下–不同窗口join的结果示意
tumbling window(滚动窗口):
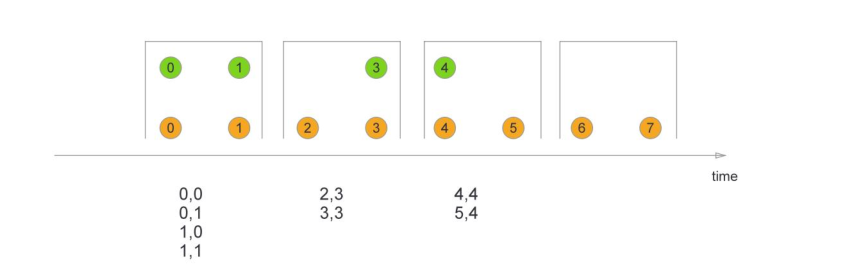
sliding window(滑动窗口):
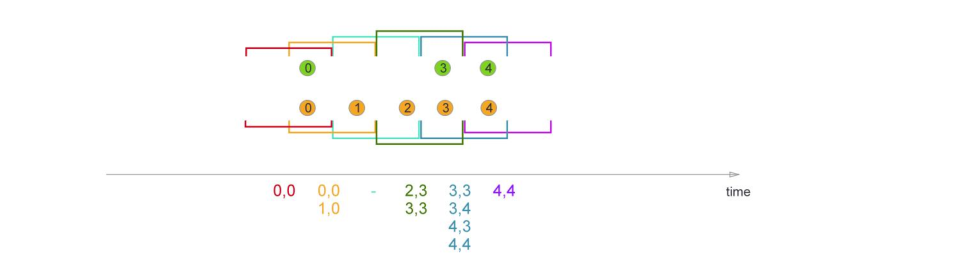
session window(会话窗口):
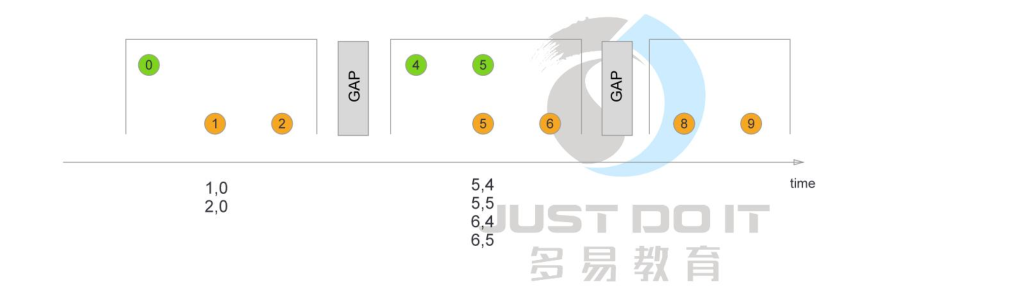
完整实例代码:
// 对 join 流进行计算处理
DataStream<String> stream = joined
// where 流 1 的某字段 equalTo 流 2 的某字段
.where(s -> s.getId()).equalTo(s -> s.getId())
// join 实质上只能在窗口中进行 .window(TumblingProcessingTimeWindows.of(Time.seconds(20)))
// 对窗口中满足关联条件的数据进行计算
.apply(new JoinFunction<Student, StuInfo, String>() {
// 这边传入的两个流的两条数据,是能够满足关联条件的
@Override
public String join(Student first, StuInfo second) throws Exception {
// first: 左流数据 ; second: 右流数据
// 计算逻辑
// 返回结果
return
}
});
3.7 broadcast广播
在开发过程中,如果遇到需要下发/广播 配置、规则等低吞吐事件流到下游所有task时,就可以使用Broadcast State特性。下游的task接收这些配置、规则并保存为BroadcastState,将这些配置应用到另一个数据流的计算中。
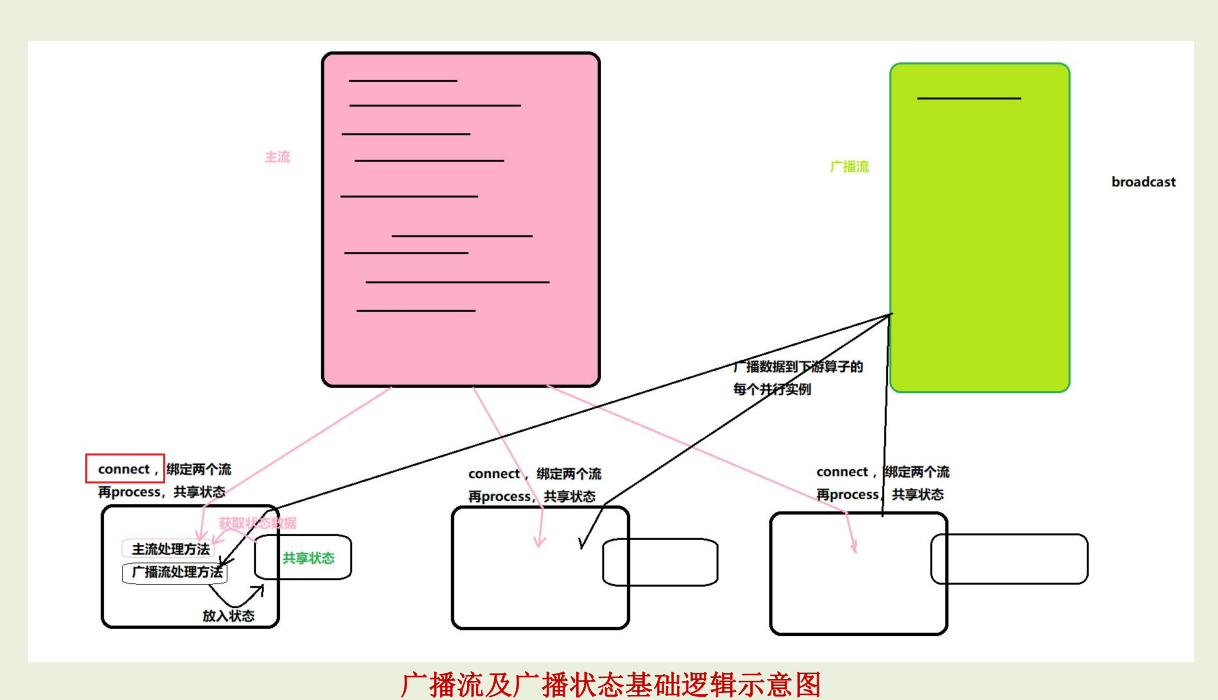
核心要点:
- 将需要广播出去的流,调用broadcast方法进行广播转换,得到广播流BroadCastStream
- 然后在主流上调用connect算子,来连接广播流(以实现广播状态的共享处理)
- 在连接流上调用process算子,就会在同一个ProcessFunction中提供两个方法分别对两个流进行处理,并在这个ProcessFunction内实现“广播状态”的共享
实例代码:
/**
* 案例背景:
* 流 1: 用户行为事件流(用户ID,时间ID)(持续不断,同一个人也会反复出现,出现次数不定
* 流 2: 用户维度信息(用户ID,年龄,城市),同一个人的数据只会来一次,来的时间也不定 (作为广播流)
*
* 需要加工流 1,把用户的维度信息填充好,利用广播流来实现
*/
// 将字典数据所在流: s2 , 转成 广播流
MapStateDescriptor<String, Tuple2<String, String>> userInfoStateDesc = new MapStateDescriptor<>("userInfoStateDesc", TypeInformation.of(String.class), TypeInformation.of(new TypeHint<Tuple2<String, String>>() {}));
BroadcastStream<Tuple3<String, String, String>> s2BroadcastStream = s2.broadcast(userInfoStateDesc);
// 哪个流处理中需要用到广播状态数据,就要 去 连接 connect 这个广播流
BroadcastConnectedStream<Tuple2<String, String>, Tuple3<String, String, String>> connected =
s1.connect(s2BroadcastStream);
/**
* 对 连接了广播流之后的 ”连接流“ 进行处理
* 核心思想:
* 在 processBroadcastElement 方法中,把获取到的广播流中的数据,插入到 “广播状态”中
* 在 processElement 方法中,对取到的主流数据进行处理(从广播状态中获取要拼接的数据,拼接后输出)
*/
SingleOutputStreamOperator<String> resultStream = connected.process(new
BroadcastProcessFunction<Tuple2<String, String>, Tuple3<String, String, String>, String>() {
/**
* 本方法,是用来处理 主流中的数据(每来一条,调用一次)
* @param element 左流(主流)中的一条数据
* @param ctx 上下文
* @param out 输出器
* @throws Exception
*/
@Override
public void processElement(Tuple2<String, String> element,
BroadcastProcessFunction<Tuple2<String, String>, Tuple3<String, String, String>, String>.ReadOnlyContext
ctx, Collector<String> out) throws Exception {
// 通过 ReadOnlyContext ctx 取到的广播状态对象,是一个 “只读 ” 的对象;
ReadOnlyBroadcastState<String, Tuple2<String, String>> broadcastState = ctx.getBroadcastState(userInfoStateDesc);
if (broadcastState != null) {
Tuple2<String, String> userInfo = broadcastState.get(element.f0);
out.collect(element.f0 + "," + element.f1 + "," + (userInfo == null ? null : userInfo.f0) + "," + (userInfo == null ? null : userInfo.f1));
} else {
out.collect(element.f0 + "," + element.f1 + "," + null + "," + null);
}
}
/**
*
* @param element 广播流中的一条数据
* @param ctx 上下文
* @param out 输出器
* @throws Exception
*/
@Override
public void processBroadcastElement(Tuple3<String, String, String> element,
BroadcastProcessFunction<Tuple2<String, String>, Tuple3<String, String, String>, String>.Context ctx,
Collector<String> out) throws Exception {
// 从上下文中,获取广播状态对象(可读可写的状态对象)
BroadcastState<String, Tuple2<String, String>> broadcastState =
ctx.getBroadcastState(userInfoStateDesc);
// 然后将获得的这条 广播流数据, 拆分后,装入广播状态
broadcastState.put(element.f0, Tuple2.of(element.f1, element.f2));
}
});
resultStream.print();
env.execute();
4 flink编程process function
4.1 process function概述
process function相对于前文所述的map、flatmap、filter算子来说,最大的区别是其让开发人员对数据的处理逻辑拥有更大的自由度;同时,ProcessFunction继承了RichFunction,因而具备了getRuntimeContext(),open(),close()等方法。
在不同类型的 datastream 上,(比如 keyed stream、windowedStream、ConnectedStream 等),应用 process function 时,flink 提供了大量不同类型的 process function,让其针对不同的 datastream 拥有更具针对性的功能;
ProcessFunction (普通 DataStream 上调 process 时)
KeyedProcessFunction (KeyedStream 上调 process 时)
ProcessWindowFunction(WindowedStream 上调 process 时)
ProcessAllWindowFunction(AllWindowedStream 上调 process 时)
CoProcessFuntion (ConnectedStreams 上调 process 时)
ProcessJoinFunction (JoinedStreams 上调 process 时)
BroadcastProcessFunction(BroadCastConnectedStreams 上调 process 时)
KeyedBroadcastProcessFunction(KeyedBroadCastConnectedStreams 上调 process 时)
下面这幅图将介绍 各种算子运算后所生成的datastream类型,及各种datastream类型之间的转换关系
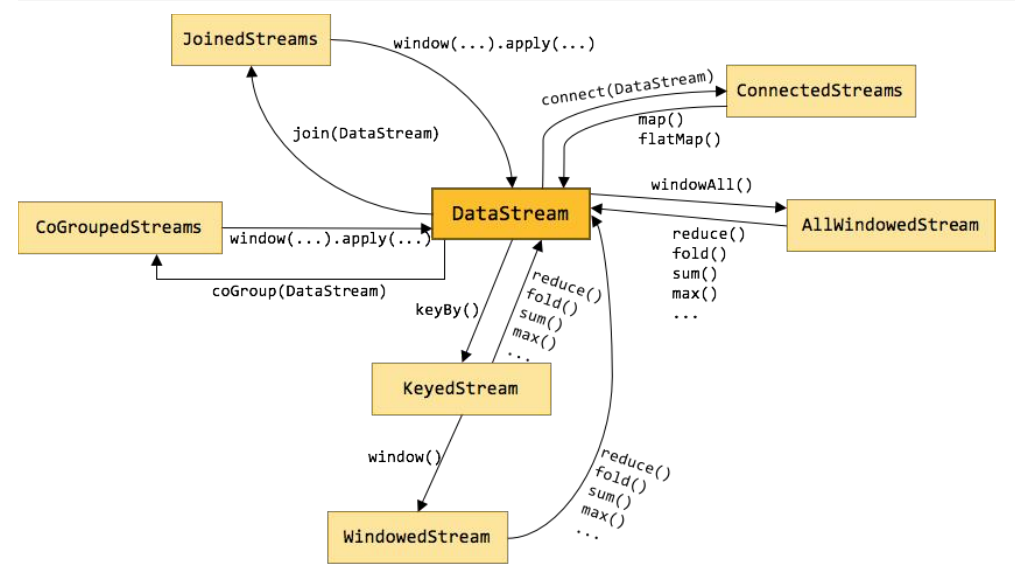
5 并行度相关概念和API
5.1 基础概念
flink执行过程:
- 用户通过算子api所开发的代码,会被flink任务提交客户端解析成JobGraph
- 然后,JobGraph提交到集群JobManager,转化成ExecutionGraph(并行化后的执行图)
- 然后,ExecutionGraph中的各个task会以多并行实例(subTask)部署到TaskManager上执行
- subTask运行的位置是TaskManager所提供的槽位(task slot),槽位简单理解就是线程
重要提示:
一个算子的逻辑,可以封装在一个独立的task中(可以有多个运行时实例:subTask);
也可把多个算子的逻辑chain在一起后封装在一个独立的task中(可以有多个运行时实例:subTask);
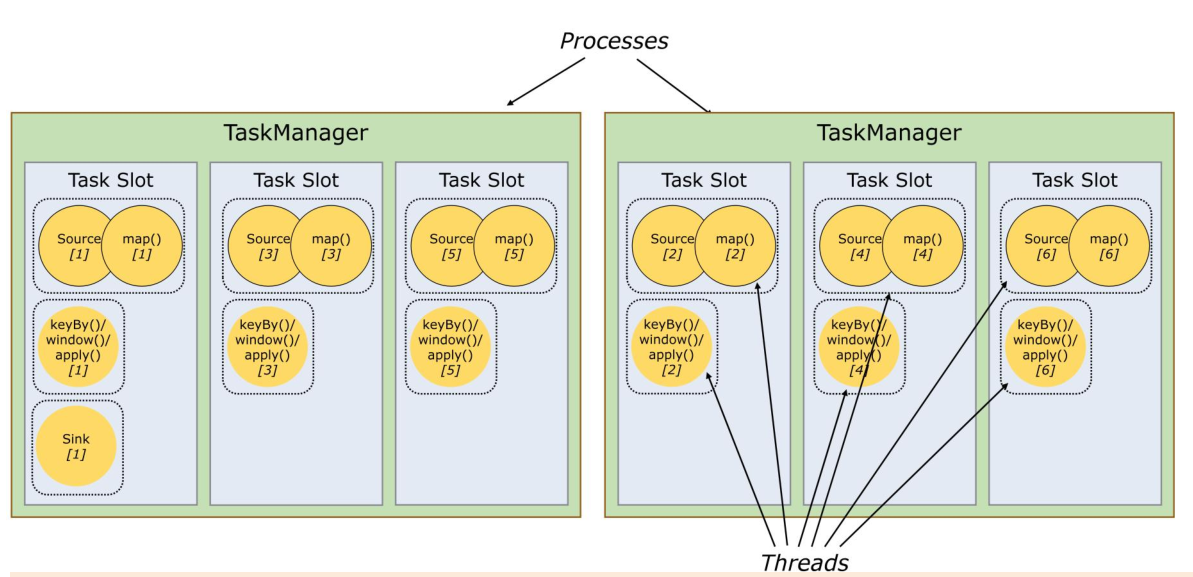
同一个task的不同运行实例,必须放在不同的task slot上运行;
同一个task slot,可以运行多个不同task的各一个并行实例。
5.2 task 与 算子链(operator chain)
上下游算子,能否chain在一起,放在一个task中,取决于如下3个条件:
- 上下游算子实例间是OneToOne数据传输
- 上下游算子并行度相同
- 上下游算子属于相同的soltSharingGroup(槽位共享组)
3个条件都满足,才能合并为一个task;否则不能合并成一个task。
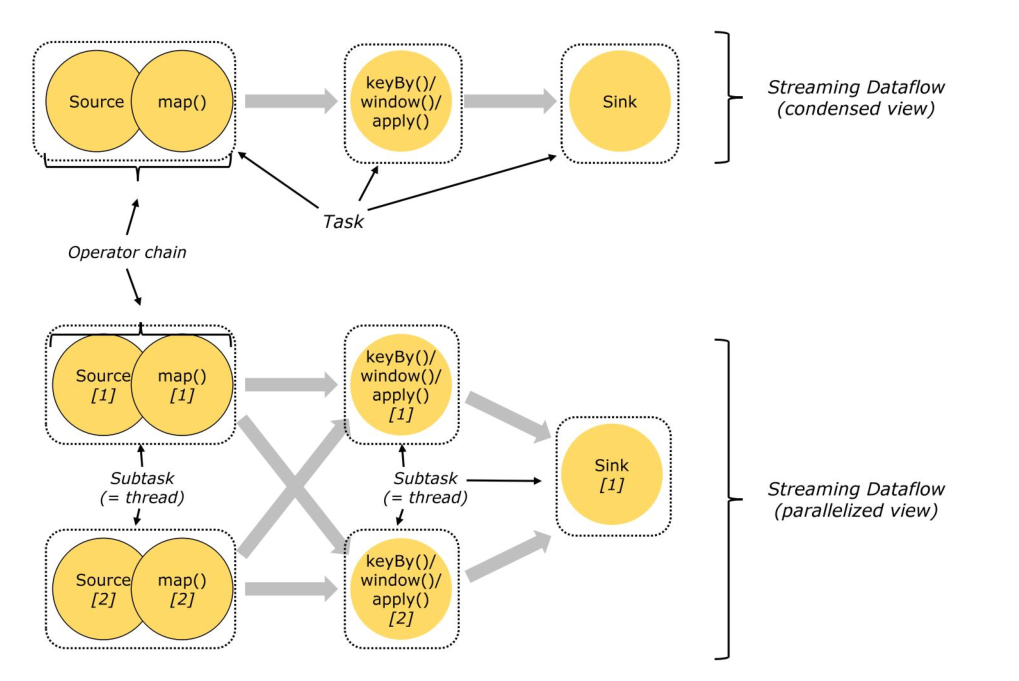
当然,即使满足上述3个条件,也不一定就非要把上下游算子绑定成算子链;
flink提供了相关的api,来让用户可以根据自己的需求,进行灵活的算子链合并或拆分:
- setParallelism 设置算子的并行度
- slotSharingGroup 设置算子的槽位共享组
- disableChaining 对算子禁用前后链合并
- startNewChain 对算子开启新链(即禁用算子前后链合并)
5.3 分区partition算子
分区算子:用于指定上游task的各并行subTask与下游task的subTask之间如何传输数据。
flink中,对于上下游subTask之间的数据传输控制,由ChannelSelector策略来控制,而且flink内针对各种场景,开发了众多ChannelSelector的具体实现
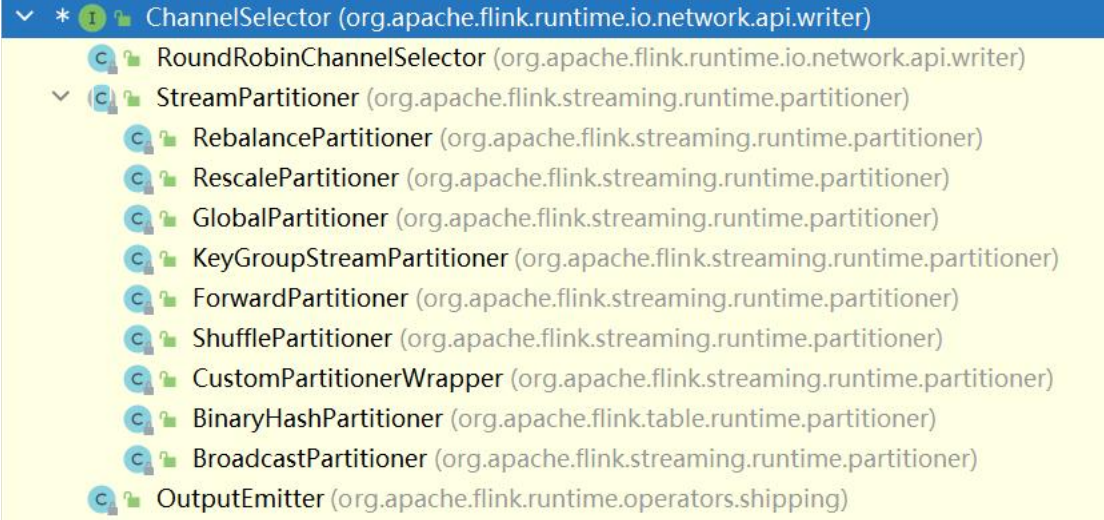
设置数据传输策略时,不需要显式指定partitioner,而是调用封装号的算子即可
dataStream.global()--全部发往第1个task
dataStream.broadcast()--广播
dataStream.forward()--上下游并发度一样时一对一发送
dataStream.shuffle()--随机均匀分配
dataStream.rebalance()--Round-Robin(轮流分配)
dataStream.recale()--Local Round(本地轮流分配)
dataStream.partitionCustom()--自定义单播
dataStream.keyBy(KeySelector)--根据key的hashcode来进行hash分发
默认情况下,flink 会优先使用 REBALANCE 分发策略
6 flink时间语义
6.1 三种时间概念
flink内部为了直观地统一计算时所用的时间标准,特制定了三种时间概念:
- processing time 处理时间
- event time 事件时间
- session time 会话时间
6.2 两种时间语义
时间语义,是flink中用于时间推进和时间判断的机制
以processing time为依据,则叫做处理时间语义
指数据被Operator处理时所在机器的系统时间
处理时间遵循客观世界中时间的特性:单调递增,恒定速度,永不停滞,永不回退
以event time为依据,则叫做事件时间语义
指数据本身的业务时间(如用户行为日志中的用户行为时间戳)
event time语义中,时间的推进完全由流入flink系统的数据来驱动
数据中的业务时间推进到哪,flink就认为自己的时间推进到了哪
它可能停滞,也可能速度不恒定,但也一定是单调递增不可回退!
时间语义的设计意义
process(EventLog eventlog){
Long eventTime = eventLog.getTimestamp();
Long processTime = System.currentMillimise()
// 用户完全可以自己根据需求中的时间定义来进行相应的计算
}
6.3 时间语义的设置
flink在需要指定时间语义的相关操作(如时间窗口时),可以通过显式的API来使用特定的时间语义:
keyedStream.window(SlidingEventTimeWindows.of(Time.seconds(5),Time.seconds(1)));
keyedStream.window(SlidingProcessingTimeWindows.of(Time.seconds(5),Time.seconds(1)));
keyedStream.window(TumblingEventTimeWindows.of(Time.seconds(5)));
keyedStream.window(TumblingProcessingTimeWindows.of(Time.seconds(5)));
event time是默认的时间语义
禁用事件时间语义
如果要禁用event time机制,则可以通过watermark生成频率间隔来实现
//如果设置为0,则禁用了watermark的生成,从而失去了event time时间语义
ExecutionConfig.setAutoWatermarkInterval(long);
7 事件时间语义中的watermark
7.1 事件时间推进的困难
事件时间,并不能像处理时间那样,由宇宙客观规律以恒定速度,不可停滞地推进。从而,在事件时间语义的世界观中,时间的推进不是一件显而易见的事
场景1
image-20230607085640053 数据时间存在乱序的可能性,但时光不能倒流!
场景2
image-20230607085722997 下游分区接收上游多个分区的数据,数据时间错落有致,那么以谁为准!


7.2 watermark来推进时间
所谓watermark,就是在事件时间语义世界观中,用于单调递增向前推进时间的一种标记
它的核心机制就是在数据流中周期性地插入一种时间戳单调递增的特殊数据元素(watermark),来不可逆转地在整个数据流中进行时间的推进
watermark是从某一个算子实例(源头)开始,根据数据中的事件时间,来周期性地产生,并插入到数据流中,持续不断地往下游传递,以推进整个计算链条上各个算子实例的时间
//watermark的生成周期(默认值为200ms)
env.getConfig().setAutoWatermarkInterval(200);
watermark,本质上也是flink中各算子间流转的一种标记数据,只不过与用户的数据不同,它是flink内部自动产生并插入到数据流的。它本身所携带的信息很简单,就是一个时间戳!
watermark产生源头示意图
初始状态
image-20230607092542524 收到一条数据后
image-20230607092603948 简单说,就是在watermark产生的源头算子实例中,实例程序会用一个定时器,去周期性地检查截止到此刻收到过的数据的事件时间最大值,如果超过了之前的最大值,则将这个最大值更新为最新的watermark,并向下游传递


watermark往下游推进示意图
初始状态
image-20230607093210265 新的上游watermark即将到达
image-20230607093157112 上游的新的watermark最终产生的效果
image-20230607093143538 一个下游算子实例,如果消费着多个上游算子实例:则选组“Min(上游各实例的最新watermark)”作为自己当前的watermark,并将自己最新的watermark向下游广播



- 标题: 关于实时计算框架flink知识的学习(1)
- 作者: 宣胤
- 创建于: 2023-04-27 16:27:07
- 更新于: 2023-06-21 00:05:17
- 链接: http://xuanyin02.github.io/2023/042717719.html
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。